We'll wrap up this chapter with a case study that brings together many themes we've explored in the Design part of this book, then finishes with an important lesson about optimization.
In August of 2003 I became interested in the problem of finding common segments in large source-code trees. There was at that time a controversy over claims that large portions of proprietary Linux kernels had been copied into Linux. To confirm or refute these assertions, I wanted a tool that could comprehensively and rapidly check for code overlaps even between code trees comprising millions of lines of C.
There is a folk algorithm, some variants of which are known as the “shred technique”[114] which attacks the problem in a clever and effective way. It relies on a property of MD5 and other cryptographic-quality checksum algorithms; if two texts have different MD5 checksums they are different, but if they have the same MD5 checksum they are almost certainly (odds of 1.8×1018) the same. A good way to think of an MD5 signature is as an unfalsifiable digital fingerprint of a text.
The basic shred technique is analogous to some methods of DNA sequencing. Chop the source trees into overlapping shreds of some small number of lines (three to five is typical; the cost of the algorithm is insensitive to variations in this figure). Generate an MD5 signature from each shred. Now throw out all the shreds that have no duplicates. Sort the remaining ones into cliques by signature value. Generate a report on the cliques. For most readable results, merge pairs of cliques when their member shreds overlap in the right way.
Variations in the algorithm begin with choosing a shred size; smaller shred sizes are more sensitive to small matches but generate noisier reports. They continue with choices about how to normalize the text before processing; it may be desirable when doing identitity analysis of C code, for example, to remove all whitespace so the comparison cannot be fooled by trivial differences in formatting or indent style. List reduction is also an issue; the original shred algorithm omits shreds that are duplicated within but not across trees in order to cut the computation costs, but thereby risks missing important common segments. Finally, the appropriate formatting for the report may vary by how the common-segment report will be used.
The program I wrote to address this problem is named comparator after an old-fashioned astronomical instrument called a “blink comparator” that was used to find moving objects in starfield photographs by flipping rapidly between shots taken at different times.[115] It is quite small, barely 1500 lines total, and is recommended for your inspection.[116] It works with a postprocessor named filterator that is under 150 lines of Python code.
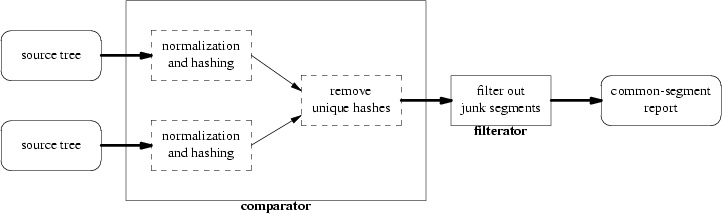
comparator can do comparisons either from raw source trees or from signature list files pre-cooked by a previous run of the tool. This has the advantage that the program can be used to do comparisons with closed-source code trees without violating the owner's copyright, provided someone with source access is willing to publish a signature list. But comparator violates the usual Unix practice by dumping this data in a binary rather than textual format.
The main reason for this is simple: the data sets involved are frequently large, so large that disk I/O is a serious bottleneck in total running time. Linux kernels, at the time I wrote this tool, clocked in at more than three million lines of code, thus around three million signatures. The obvious textual representation (lines consisting occasionally of filenames but mostly of two decimal start and end numbers, plus a 32-bit hexadecimal representation of the MD5 signature) eats about 40 bytes on average, counting field delimiters and the ending linefeed. Using a packed binary representation (two shorts and sixteen chars) cuts that to twenty bytes. At these data volumes, the roughly 50% space and time efficiency gain from smaller records and not having to do text parsing on input is actually significant.
But note that I tried both kinds of format before deciding this. Designing a binary format first-in would have been premature optimization. One good practice — trying alternatives and measuring, rather than just guessing — was enabled by another; using an interpreted rapid-prototyping language for my first cut in order to keep exploration costs low, and thus avoid getting locked into a sub-optimal design by inertia.
comparator well illustrates the advantages of mixed-language development (a theme we'll return to in Chapter 14). I built my prototype in Python and a production implementation in C. Both were planned nearly from the beginning as a correctness check on each other; the languages are so different that the natural ways of coding are liable to break on different edge cases. The Python prototype made it significantly easier to experiment with variations and get a feel for this neighborhood of design space than would have been the case if I had coded from the beginning in C, but proved too slow and memory-intensive for practical use. Neither result was surprising. Both versions are shipped in the distribution.
The interface design of comparator is a conscious instance of what we have earlier examined in Chapter 11 as the compiler-like pattern. We've observed that this is often a good fit for programs that do data conversion or translation, and comparator falls in that category. But the fit is especially comfortable here because of a natural analogy that maps source trees to source files, shred-signature lists to linkable object files, and common-segment reports to final, fully-linked executables.
The default mode of comparator is to produce a common-segment report from its arguments, just as the default behavior of a Unix compiler is to try to produce a fully-linked executable. Unix compilers generally use -c as the switch that suppresses linking, instead generating a .o file for use in a later linking operation. Accordingly, I obeyed the Rule of Least Surprise by using -c as the switch that tells comparator to generate a signature list and stop.
Going one step further, I implemented -o to do exactly what it does to the C compiler — redirect output to a named file. By providing these two options, rather than just -c, I make it easier for an experienced Unix user to spot that analogy during a cursory scan of the manual page. While this option has some direct utility in unusual cases, the main point of implementing it was precisely that psychological one — to make comparator feel instantly more comfortable in the hand to people who know what C compiler command lines look like. If comparator had any analogue of inserting debugging or trace information in signature lists, I would certainly have mapped over the C compiler'a -g option.
The C compiler also inspired the output format of the common-segement reports. By adopting the same format as C compiler error reports (filename followed by colon followed by line number) I made the output look friendly to every C programmer. Just as importantly, obeying the Rule of Least Surprise here also satisfied the Rule of Composition; it made the output immediately parseable by tools intended to consume C compiler errors — notably, the next-error function of Emacs. If you drop a comparator report into an Emacs compile buffer, you can step through the locations it refers to with the same commands you would normally use to step through errors. This makes it easy to eyeball-scan even rather large collections of common segments. The cliches of Unix are your friends.
comparator also provides us with a case study in when it is wise to do the opposite of normal Unix practice and coalesce two small programs into a big one. The prototype was actually two Python scripts, shredtree to generate signature lists and shredcompare to merge them and throw out non-duplicates. The C implementation comparator started out as a similar pair, but is now a single program that does both things depending on its mode of invocation.
Again, the reasons have to do with the large data-set sizes. I originally wrote the program as a pair of scripts for the best of Unixy reasons, to hold down global complexity. I also expected that reading signature files would prove faster than re-shredding source trees every time. To my considerable surprise, the latter expectation turned out to be mistaken. Apparently the overhead of writing and then reading a flat five-million-record signature list file is not very different from that of doing a walk through its source tree. In fact, the flat-file read appeared often to take longer!
Why this was so remains obscure; possibly the big continuous reads fell into some sort of unpleasant resonance with the operating system's scheduler. But the cure was clear — not to drop the signature list out of memory in the normal case! Accordingly I fused the two C programs into one, and made the default behavior and end-to-end generation of a common-segment report, with override switches for generating signature lists. It was at this point that the analogy to the C compiler became clear.
One of the good reasons to build larger programs — indeed, perhaps the only good reason — is when passing a large amount of shared data or context among smaller programs would involve a substantial performance or complexity-management overhead. We'll return to this point in Chapter 13.
There was, however, a third piece of the original script set that I never considered abandoning or lumping into the main program. That was shredcompare, the prototype script that became filterator.
The job of filterator is to interpret the raw common-segments report from comparator into something more readable, throwing out segments we can mechanically determine to be trivial. Turning this into C and welding it to comparator would have been a serious mistake. Because the data sets it sees from the output end of comparator are relatively small, there is no performance need to translate it into a fast but low-level language. The Rule of Economy would have told me to leave it in Python on these grounds alone.
But there was another more important reason for leaving filterator in a scripting language. Its requirements seemed far more likely to vary over time than would those of comparator.
At bottom, the job comparator does is rather simple and mechanical. Not so with filterator; there could be many different theories of what makes a common segment significant enough to be worth including in a final report. Which theory is applicable could vary a great deal, and might (for example) be affected over time by court decisions about the boundaries of software copyright infringement.
Accordingly, the single most important measure of merit for the filterator program over the long term will probably be how readily and rapidly it can be modified to meet changing requirements. And that is a conclusive case for sticking with a scripting language like Python, Perl, or Tcl.
An astute reader who has already looked over the comparator manual page will wonder why I didn't factor out normalization — input filtering — in the same way. After all, comparator could have been designed to call a normalizer script on each input file. Instead, there is just one normalization option, the -w to strip whitespace.
An even more astute reader who has absorbed the argument about why filterator is a separate program might already have formed one hypothesis; the input data sets of comparator are much larger than the input data sets of filterator, and calling a filter symbiont on every input file in a large tree might well extract enough of performance penalty to make using the tool unpleasant.
While this is plausible,it's not the primary reason for the asymmetry. No; the real reason that normalization is in the C code is that though some normalizations could change line numbers in the filtered code, we want the final report to refer to the line numbers before normalization. Thus, the C code has to know what the original code looks like and track any line deletions and insertions done by the normalization code.
The theme of this chapter is optimization, so the most important and final lesson of this case study is the source of its surprising performance. The most remarkable thing about comparator is that it is fast. Really fast. In fact it is almost ridiculously fast; I have observed on a stock 1.8GHz Athlon box processing rates equivalent to four million line comparisons a second. The one competing implementation of the shred algorithm that I have studied carefully is five to ten times slower than this.
The reason appears to be that this other implementation took the computer-science grad student approach to the challenge of detecting signature cliques. That is, brew up a clever custom data structure that is optimized for your special lookup problem. Play games with hash tables or (more plausibly in this case) B-trees. The background assumption is that you must stick with incremental, local operations on your data set because marching through all the data is bound to be too expensive. The hacker who wrote it was careful and good; his thoughtful notes on the design quickly disposed of any theory that I was comparing myself against an incompetent.
One problem with this grad-student approach is that it is more expensive than it looks. Memory that is storing the link pointers for a hash bucket or tree structure is not storing real data. Just as code you can avoid writing is the best time optimization, data structures you can avoid instantiating are the best space optimization.
But I, too, initially made this mistake. When the dictionary-based implementation of signature lookups in Python proved too slow, I designed an elaborate hash-table-based data structure in C. I was beginning to implement it when I stopped short and asked myself what the simplest way I could do this would be. I had seen the complicated way as implemented by someone with taste and intelligence, but I didn't much like the results. Somewhere in the back of my brain, Ken Thompson was whispering “When in doubt, use brute force.”
So I asked myself not “what is the elegant solution?” but “What is the brute-force solution?” And I found it. It's a big, stupid sort pass.
The problem is sorting structures keyed by an MD5 signature into cliques by signature, and tossing out the singletons. The insight is that if you sort the shreds by signature, all the cliques will turn into spans of adjacent shreds. In effect, all of your signature lookups get done at once, in parallel, with a single call to the qsort(3) library routine, instead of having to be done one at a time as the shreds are processed in. A simple linear-time walk through the sorted data will extract the interesting cliques.
This approach is simple and, as previously noted, turns out to be astonishingly fast. Sorting six million shreds talkes less than 18 seconds of wall time. Quicksort is O(n log n) on average; we are very unlikely to tickle its notorious O(n2) worst case because it is very unlikely that a list of text signatures will by nearly ordered already. Individual searches in a B-tree are O(log n), so searching for every key as it comes in should also be about O(n log n). Now we know why a big stupid quicksort is no slower than a fancy lookup data structure; the question that remains is why brute force is up to an order of magnitude faster.
The answer appears to be working-set size. When your raw data takes up a significant portion of core by itself, the additional overhead of a fancy data structure can push your memory usage to the point where it triggers a lot of swapping. This is not mere conjecture; the specific reason the Python implementation was too slow to use was that on real (e.g., large) data sets the virtual-memory system thrashed like crazy. Python objects are space-expensive; the working-set size was simply too big for the system to handle gracefully.
The virtue of the big stupid sort is that it packs real data into the smallest working set that could possibly hold it, then rearranges that data in place so the working set never gets significantly larger. This is where our discussion of the harmfulness of nonlocality earlier in this chapter comes home to roost. The extra space overhead of the B-tree and its kin may be a losing proposition as changes in cost gradients make computation ever cheaper but increase the relative cost of memory references — especially memory references that break a cache boundary, and most especially references that can tip your virtual-memory system into thrashing.
The most general lesson of this case study is therefore that when optimizing, the direction of technology is such that it is it is increasingly wise to look for simple, computation-intensive techniques rather than being clever and economical with compute cycles at the cost of a larger working set, more nonlocality, and (incidentally) more complex code. Ken Thompson was right, and once again the Zen of Unix demands that we unlearn excessive cleverness. In the the land of the fast machine, brute force is king.
[114] Unusually, the shred algorithm seems to have been first publicly described by an anonymous contributor in a computer-industry tabloid: see http://theinquirer.net/?article=10061