Abstract
Note: This is a draft under intensive development. Some claims made in it may be incorrect. Others may be correct but insufficiently sourced. Corrections and feedback are welcomed,
A guide to the history and taxonomy of version-control systems available on Unix-family operating systems. This document is meant to help readers make sense of the version-control landcape and the conflicting claims flying around it, and to help the reader make informed choices. VCS designs analyzed include SCCS, RCS, DSEE/ClearCase, CVS, Subversion, Arch, ArX, monotone.
Table of Contents
A version control system (VCS) is a tool for managing a collection of program code that provides you with three important capabilities: reversibility, concurrency, and annotation.
The first VCSes were built as support technology for computer programmers, and that is still their primary use, but they can be used for Web content or any other sort of document or data file stored on a computer. Modern VCSes, in particular, fully support managing binary files such as images.
The most basic capability you get from a VCS is reversibility, the ability to back up to a saved, known-good state when you discover that some modification you did was a mistake or a bad idea.
VCSes also support concurrency, the ability to have many people modifying the same collection of code or documents knowing that conflicting modifications can be detected and resolved.
Finally, VCSes give you the capability to annotate your data, attaching explanatory comments about the intention behind each change to it and a record of who was responsible for each change. Even for a programmer working solo, change histories are an important aid to memory; for a multi-person project they become a vitally important form of communication among developers.
A VCS gives you these capabilities by storing master copies of your files in a repository that stores their change histories. You will not alter that repository directly; instead, you will edit working copies made from the repository contents.
There are three basic things you can do with a VCS; check out a workfile copy from a repository, check in or commit a change in a workfile to its master in a repository, and view history of files. Everything else VCSes do is an elaboration or support for those three operations.
An important capability of all but the earliest VCSes is that the repository for your files need not be local to you; it can be on a different machine on the same local network, or a thousand miles away over the Internet.
VCSes can be distinguished from document management system oriented more towards natural-language documents; these tend to be VCS-like programs with only rudimentary change tracking, an emphasis on search features, a GUI, and a high price tag. We won't cover these in this survey.
It is a bit more difficult to distinguish VCSes from Software Configuration Management (SCM) systems. Though the terms are sometimes used interchangeably, “SCM” is more properly used for tools which combine VCS features with support for automating product builds and for issue and bug tracking.
We will not cover full-fledged SCMs in this survey, as its intended audience expects their added functions to be broken out into orthogonal components such as Unix make and Bugzilla. It is worth noting, however, that the earliest VCSes evoloved from early SCMS by simplification, and that (at least outside the Unix world) VCSes have shown a tendency to accrete SCM features over their lifetimes.
An important capability that distinguishes VCS from document-management systems is that all VCSes (even the earliest and most primitive) have some notion of branches. The history of a file (or in later systems, a group of files) need not be a simple linear sequence from first revision to latest; it can have points where the history forks into alternate “what-if” versions. Programmers use branching to develop experimental and stable versions of code in parallel. More advanced systems provide automated assistance with merging branches.
There are three fundamental ways ways in which VCSes can differ from each other. They can be centralized or decentralized; they can be locking, merge-before-commit, or commit-before-merge; and they can do file operations or fileset operations.
In second- and third-generation systems, there are two subtler sets of issues. Some VCSes are snapshot-based and some are changeset-based. Some have container identity and other do not.
Early VCSes were designed around a centralized model in which each project has only one repository used by all developers. All “document management systems” are designed this way. This model has two important problems. One is that a single repository is a single point of failure — if the repository server is down all work stops. The other is that you need to be connected live to the server to do checkins and checkouts; if you're offline, you can't work.
The very earliest first-generation VCSes supported local access only; that is, all developers of a project needed to be on the same machine as the single central project repository. Second-generation VCSes, while still centralizing each project around a single repository, supported a client-server model allowing developers to work with it over a network from other machines.
Newer, third-generation VCSes are decentralized. A project may have several different repositories, and these systems support a sort of super-merge between repositories that tries to reconcile their change histories. At the limit, each developer has his/her own repository, and repository merges replace checkin/commit operations as a way of passing code between developers.
An important practical benefit is that such systems support disconnected operation; you don't need to be on the Internet to commit to the repository because you carry your own repository around with you. Pushing changesets to someone else's repository is a slower but also less frequent operation.
A version control system must have some mechanism to prevent or resolve conflicts among users who want to change the same file. There are three distinct ways to accomplish this.
With version-control locking, workfiles are normally read-only so that you cannot change them. You ask the VCS to make a work file writable for you by locking it; only one user can do this at any given time. When you check in your changes, that unlocks the file, making the work file read-only again. This allows other users to lock the file to make further changes.
When a locking strategy is working well, workflow looks something like this:
Alice locks the file
foo.cand begins to modify it.Bob, attempting to modify
foo.c, is notified that Alice has a lock on it and he cannot check it out.Bob is blocked and cannot proceed. He wanders off to have a cup of coffee.
Alice finishes her changes and commits them, unlocking
foo.c.Bob finishes his coffee, returns, and checks out
foo.c, locking it.
Unfortunately workflow too often looks more like this:
Alice locks the file
foo.cand begins to modify it.Bob, attempting to modify
foo.c, is notified that Alice has a lock on it and he cannot check it out.Alice gets a reminder that she is late for a meeting and rushes off to it, leaving
foo.clocked.Bob, attempting to modify
foo.c, is notified that Alice has a lock on it and he cannot check it out.Bob, having been thwarted twice and wasted a significant fraction of his day waiting on the lock, curses feelingly at Alice. He informs the VCS he wants to steal the lock.
Alice returns from the meeting to find mail or an instant message informing her that Bob has stolen her lock.
Changes in Alice's working copy are now in conflict with Rob's and will have to be merged later. Locking has proven useless.
That, unfortunately, is the least nasty
failure case. If the VCS has no facility for stealing locks, change
conflict is prevented but Bob may be blocked indefinitely by Alice's
forgotten lock. If Alice is not reliably notified that her lock has
been stolen, she may continue working on foo.c
only to receive a rude surprise when she attenpts to commit it.
Most importantly, in these failure cases locking only defers
conflicts that must be resolved by merging divergent changes to
foo.c after the fact — it does not prevent
them. It scales poorly and tends to frustrate all parties.
Despite these problems, locking can be necessary and appropriate when conflict merging is effectively impossible. This is often the case when the workfile is something non-textual, such as an image. To handle that case, some VCSes have optional locking, without a lock-stealing escape mechanism) as a fallback, that must be explicitly requested by the user rather than being done implicitly on checkout.
Historically, locking was the first conflict-resolution method to be invented, and is associated with first-generation centralized VCes supporting local access only.
In a merge-before-commit system, the VCS notices when you are attempting a commit against a file or files that have changed since you started editing, and requires you to resolve the conflict before you can complete the commit.
Workflow usually looks something like this:
Alice checks out a copy of the file
foo.cand begins to modify it.Bob checks out a copy of the file
foo.cand begins to modify it.Alice finishes her changes and commits them.
Bob, attempting to commit the file, is informed that the repository version has changed since his checkout and he must resolve the conflict before his commit can proceed.
Bob runs a merge command that applies Alice's changes to his working copy.
Alice's and Bob's changes to
foo.cdo not actually overlap. The merge command returns success, and the VCS allows Bob to commit the merged version.
Empirically, actual merge conflicts are unusual. When they do occur, a merge-before-commit VCS will typically put both spans of conflicting lines in Bob's workfile with some kind of conspicuous marker around them, and refuse to accept a commit until Bob has edited out the marker.
Historically, merge-before-commit was the second conflict-resolution method to be invented and is associated with centralized client-server VCSes.
It is possible to design a VCS so it never blocks a commit. Instead, if the repository copy has changed since the files(s) were checked out, the commit can simply be shunted to a new branch. Subsequently, the branches may remain separate; or, any developer may perform a merge that brings them back together.
Alice checks out a copy of the file
foo.cand begins to modify it. For illustrative purposes, let's say the revision before Alice's workfile was numbered 2. The state of the project now looks like this:
The boxes indicate versions of
foo.c, the solid arrow indicates the “is a revision of” relationship in the repository, and the dotted arrow represents the checkout to Alice's working area.Bob checks out a copy of the file
foo.cand begins to modify it. The repository now looks like this:
Alice finishes her changes and commits them. The repository now has a version 3.

Bob, attempting to commit changes to
foo.c, is informed that the repository version has changed since his checkout and his commit began a new branch. His revision is numbered 4. Alice and Bob now have peer branches in the repository.
Bob compares Alice's branch with his and decides the changes should be merged. He runs a merge tool to do so. When he successfully exits the merge tool, a new version of
foo.cis committed that is marked as a descendant of both 3 (Alice's version) and 4 (Bob's version).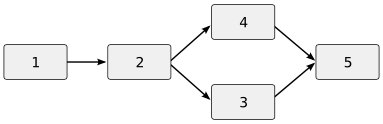
If a third developer, Carol, checks out
foo.c after Bob's merge, she will retrieve the
merged version.
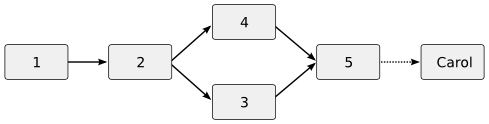
The commit-before-merge model leads to a very fluid development style in which developers create and reconverge lots of small branches. It makes experimentation easy, and records everything developers try out in a way that can be advantageous for code reviewing.
In the most general case, a repository managed by a commit-before-merge VCS can have the shape of an arbitrarily complex directed acyclic graph (DAG). Such VCSes often do history-aware merging, using algorithms that try to take account not just of the contents of the versions veing merged but of the contents of their common ancestors in the repository DAG.
The model is not completely without own pitfalls, however. If another developer, David, decides to try merging revisions 3 and 4 at the same time as Bob, he might produce a different merge. Supposing David's merge is finished after Bob's, it will become version 6 and the repository will look like this:
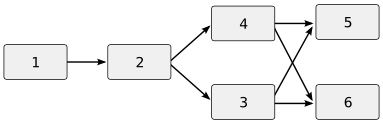
The variant versions 5 and 6 may now need to be be reconciled. This leads to an awkward case called a cross-merge which tends to confuse history-aware merging tools.
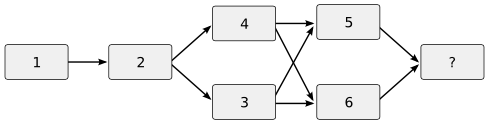
The commit-before-merge model is associated with third-generation decentralized VCSes and quite new, having emerged about 1998.
In early VCSes, some of which are still in use today, checkins and other operations are file-based; each file has its own master file with its own comment- and revision history separate from that of all other files in the system. Later systems do fileset operations; most importantly, a checkin may include changes to several files and that change set is treated as a unit by the system. Any comment associated with the change doesn't belong to any one file, but is attached to the combination of that fileset and its revision number.
Filesets are necessary; when a change to multiple files has to be backed out, it's important to be able to easily identify and remove all of it. But it took some years for designers to figure that out, and while file-based systems are passing out of use there are lots of legacy repositories using file-centric VCSes still to be dealt with at time of writing in early 2008.
In a VCS with container identity, files and directories have a stable internal identity, initialized when the file is added to the repository. This identity follows them through renames and moves. This means that filenames and directories are versioned, so that it is possible (for example) for the VCS to notice while doing a merge between branches that two files with different names are descendants of the same file and do a smarter merge of their contents.
Container identity can be implemented by giving each file in the repository a “true name” analogous to a Unix inode, Alternatively, it can be implemented implicitly by keeping all records of renames in history and chasing through them each time the VCS needs to check what file X was called in revision Y.
Absence of container identity has the symptom that file rename/move operations have to be modeled as a file add followed by a delete, with the deleted file's history magically copied during the add.
Usually VCSes that lack container identity also create parent directories on the fly whenever a file is added or checked out, and you cannot actually have an empty directory in a repository.
There are two ways to model the history of a line of development. One is as a series of snapshots of an evolving tree of files. The other is as a series of changesets transforming that tree from a root state (usually empty) to a tip state.
Change comments, and metadata associated with them such as the author of the change and a timestamp, may be associated either with a snapshot or with the changeset immediately before it. From a user's point of view the difference is indistinguishable.
Changeset-based systems have some further distinctions based on what kinds of data a changeset carries. At minimum, a changeset is a group of deltas to individual files, but there are variations in what kind of file-tree operations are represented in changesets.
Changesets which include an explicit representation of file/directory moves and renames make it easy to implement container identity. (Container identity could also be implemented as a separate sequence of transaction records running parallel to a snapshot-sequence representation, but I know of no VCS that actually does this.)
As a lesser issue, a changeset-based system may either model file additions as a delta from the empty file and file deletions as a delta to an empty file, or the changeset may explicitly record adds and deletes.
Snapshot and changesets are not perfectly dual representations. It took a long time for VCS designers to notice this; the broken symmetry was at the core of a well-known argument between the designers of Arch and Subversion in 2003, and did not begin to become widely understood until after Martin Pool's 2004 essay Integrals and Derivatives. Pool, a co-author of bzr, correctly noted that attempts to stick with the more intuitive sequence-of-snapshots representation have several troubling consequences, including making container identity and past merges between branches more difficult to track.
This section is a guide to basic version-control terminology. It has two aims: (1) to define some terminology we will be using in comparisons later on, and (b) to show that several common terms that look like they might be describing different concepts are actually pointing at the same thing. A more comprehensive glossary is available at revctrl.org.
- check-in
The act of sending a working copy (a workfile or set of workfiles) to your repository to become a permanent part of its history
- commit
A synonym for check-in. Tends to be associated with more modern systems with fileset operations.
- version
A file, or set of files, as they existed at the time of a check-in operation. Associated with a version will be metadata such as a version number and a timestamp.
- revision
A synonym for “version”; or, interchangeably, for the version's number. Some VCSes that use version numbers of the form >“M.N” refer to the M or major part as version and the N or minor part as revision, but this is mainly historical.
- trunk
The main branch of a revision history; the trunk of the tree.
- tip
The latest version in a branch.
- head
Synonym for “tip”; the latest version in a branch. This term tends to be used more when you're talking about the trunk, “tip” more when you're talking about a non-trunk branch.
- delta
A description of changes between two versions of an individual file, usually as a sequence of line-oriented additions and deletions and replacements. Such line-oriented deltas are often represented in a standard notation derived from the output format of the Unix diff(1) command. There is a well-defined concept of deltas between binary files as well, but no standard human-readable notation for expressing them.
- working version
The repository version that your workspace copy was checked out from. Not necessarily the same as the head or tip version; the user may have chosen to check out from an older one, perhaps with the intention of starting a new branch.
- keywords
Keywords are magic text strings that can be inserted in a version-controlled file; when the file is checked out, they will be replaced by various pieces of metadata associated with the checkout, such as its author or revision ID or the time of last checkin.
The following is not an exhaustive history; there have been dozens of VCSes built since the concept was invented, most obscure and proprietary. We'll concentrate here on the open-source VCSes that have led up to today's leading-edge systems, mostly ignoring those which in retrospect turned out to be false starts or dead ends. We will cover, though not necessarily in as much depth, some of the more influential closed-source systems as well.
Note on orthography: While some names of VCSes are normally capitalized and others are all-caps acronymes, several are by convention normally left in all lower case. I have tried to follow the usage preferred by their designers in each case.
The common trait of first generation of VCSes was that they were all file-oriented and centralized. Most were locking-based, with merging-based systems arriving towards the end of that era.
Version-control systems are loosely derived from change-management and logging systems used on mainframes in the 1960s; these connections are sketched in Walter Tichy's RCS paper. It is worth noting that the very first VCS, while it later became closely associated with the Unix operating system, was originally written on an IBM System/370 computer running OS/MVT.
In the beginning was SCCS, the Source Code Control System. It was written in 1972 by Marc Rochkind, one of the early Unix developers at Bell Labs. SCCS was locking, file-oriented, and centralized; in fact, it had no support for remote (networked) repositories, a capability that was not even really imagined until the post-1982 rise of the Internet.
SCCS, originally written in an IBM mainframe environment, was distinct from earlier mainframe-based change-tracking systems in that it was specifically designed to manage software and had a well-defined notion of revision history with a unique identifier for each revision. These features still define VCSes today.
SCCS has long since passed out of general use, but it pioneered concepts and conventions that are still very much with us. To this day, many VCSes still use SCCS-style version numbering, a major version and a minor version (or revision) separated by a period.
Early SCCS was, like Unix itself, officially proprietary but de-facto open source until about 1985. A direct descendant of the original Bell Labs code is now open source in OpenSolaris; a slightly cleaned-up version of the Solaris code is available as This standalone project. There is one open-source clone, the written-from-scratch CSSC (Compatibly Stupid Source Control). CSSC is mainly intended to help SCCS users migrate to newer systems.
RCS, the Revision Control System, was the second VCS to be built and the oldest still in common use. It was written by Walter F. Tichy at Purdue University during the early 1980s. (The sources of rcs-5.7 include a note that RCS version 3 was released in 1983; its earlier history remains obscure.) Like SCCS, to which it was a direct response, RCS is locking, file-based, and centralized with no capability for network access.
Unlike SCCS, RCS is still in fairly widespread use in 2008. RCS is lightweight and low-overhead compared to more recent and more capable — but also more elaborate — VCSes. The command interface, while primitive, is cleaner than that of SCCS. The document source for this survey itself was kept under RCS before being split into multiple files moved to Mercurial, and that is typical of its modern use cases; programmers often rely on it to keep histories of single documents or small programs that they are maintaining single-handed.
RCS was open-source from the beginning and is still commonly installed on Linux and Unix systems today. There is an Official RCS Homepage.
DSEE (Domain Software Engineering Environment) was a VCS with significant SCM features including a build engine and a task tracker, first released in 1984 on Apollo Domain workstations. After Apollo was acquired by HP in 1989, DSEE continued to be used extensively within HP. The DSEE team was eventually allowed to spin off and became Atria; DSEE was rebranded as ClearCase. Later, Atria was acquired by IBM and continues to be in wide use in 2008 under the name Rational ClearCase.
While DSEE/ClearCase are proprietary and closed source, they are interesting to examine because they represent a sort of apex of first-generation VCS design. At least one significant feature, the representation of repostories as a special filesystem using magic pathnames encoding revision levels and other metadata, is not found in later designs and is still somewhat interesting.
RCS predated ubiquitous networking and did not scale up well to collaborative development. These were becaming important around 1985 just as Tichy's RCS paper and production releases were becoming well-known. Dick Grune, a professor at the Free University of Amsterdam, wrote some script wrappers around RCS in 1984-1985 to address these problems. Two years later Brian Berliner turned these scripts into C programs which became the basis for later versions of what became known as the Concurrent Versions System.
CVS began to see wide use around 1989-1990, but still in a local mode (client and repository on the same machine). It did not become really ubiquitous until after Jim Blandy and Karl Fogel (later two principals of the Subversion project) arranged the release of some patches developed at Cygnus Software by Jim Kingdon and others to make the CVS client software usable on the far end of a TCP/IP connection from the repository. This was in late 1994, just after the first big wave of Internet buildout. Thereafter, CVS reigned more or less unchallenged in open-source development for about ten years, until Subversion 1.0 shipped in 2004.
CVS was file-oriented and centralized, like its predececessors, but broke new ground by being designed for collaborative development using a merging rather than locking-based approach. Almost all subsequent systems have followed this lead, adopting CVS terminology and conventions and even the style of its command-line interface.
With these advances, however, also came significant problems. Moving or renaming files in a CVS archive was poorly supported and could cause serious trouble. But that was a symptom; the underlying problem was the file-oriented assumptions baked into CVS's lower layers. By the late 1990s it had been clear for years that CVS's architecture was simply not strong enough to support what it was aiming to do, and developers began casting about for a successor.
CVS was open-source from the beginning and is still commonly installed on Linux and Unix systems today. It is maintained by Purdue University and the Free Software Foundation. It is still in very wide use in 2008, but is losing ground rapidly to second- and third-generation systems.
There were several attempts to rescue the CVS codebase and its basic architecture beginning in the late 1990s: Meta-CVS, and CVSNT were the best known. All of these failed, neither solving CVS's architectural problems in a convincing way nor achieving significant mind-share among developers. A new approach was needed.
In 2000, a group including some former CVS core developers launched Subversion, a project explicitly intended to improve on and supersede CVS. Subversion is also known as SVN, after the directory name its repositories conventionally use. While their first official production release did not arrive till 2004, betas from about 2002 onward were usable; in fact, it became clear the project was going to succeed at its major goals well before the 1.0 version shipped.
In a move that proved politically very shrewd, Subversion did its best to hide its differences from CVS; its command-line interface is so close to CVS's that a CVS user can utter basic commands with confidence within minutes of hearing SVN explained or reading a cheat sheet.
Relatedly, one of the effects of Subversion was to reform and to some extent standardize version-control jargon, as well the style of command-line interfaces. In this they built on, extended, and cleaned up CVS terminology.
Despite certain serious weaknesses which we'll examine later in the Comparisons section, SVN's combination of interface conservatism and innovation under the hood proved to be exactly what dissatisfied CVS users needed. The Subversion developers played their hand well, largely avoiding serious blunders or bugs. As a result, 2003 to 2007 saw a large-scale migration from CVS to SVN and the effective death of all other CVS alternatives. At time of writing in early 2008 there are actually more active SVN than CVS projects, and it is generally understood that CVS's days are numbered.
However, in the longer term so are Subversion's. It is clearly the best of the centralized VCSes, but just as clearly the last of its kind. As dispersed, Internet-mediated software development becomes the norm rather than the exception, the centralized model of version control is running out of steam as visibly as the file-centric one did with CVS in the 1990s.
SVK is a layer on top of Subversion that implements decentralized/disconnected operation and more powerful merging operations. In much the same way that CVS used RCS as file-storage infrastructure to implement a more advanced model of version control than RCS supported, SVK uses Subversion to implement a more powerful model than Subversion alone can support.
But, like CVS, SVK is something of an amphibian. I group it with Subversion because, unlike the third-generation systems we'll look at in a bit, it's not truly decentralized. Like CVS, it inherits some of the design limitations of its underlayer.
Chia-liang Kao began work on the system in September 2003, He describes his design decisions in Distributed Version Control with svk. While SVK has attracted generally favorable reviews, it has yet to score design wins in major projects as of mid-2007.
Third-generation VCSes are natively decentralized. At time of writing there are many competing projects in this space; BitKeeper, git, monotone, darcs, Mercurial, and bzr, are the best known. All but BitKeeper are open-source. Some winners are beginning to emerge.
Arch (with BitKeeper) pioneered the diagnostic traits of third-generation VCSes. It was merging-based, changeset-based, and fully decentralized. Tom Lord, the author of Arch, had a firm grasp on the concept of a “changeset” in 2002, and may have been the person who popularized the term (though BitKeeper had used it years earlier).
Unfortunately, the Arch design became notorious for both brilliant ideas and a user interface that was poorly documented, complex, and difficult to work with. Even more unfortunately, Tom Lord shared all of these traits, both positive and negative.
Early sources were publicly available in January 2002, when Tom Lord responded to notice of his original implementation in shell (larch) on the Subversion mailing list. During the next three years, Lord's specification for the behavior of his system (“Arch 1.0”) was reimplemented in a number of different languages. Daughter versions included Robert Collins's barch (C) Federico Di Gregorio's eva (Python), Walter Landry's ArX (C++), Robert Collins's baz (C), Martin Pool's bzr (Python, and a further departure than the rest), and Tom Lord & Andy Tai's GNU Arch 1.x aka tla (C).
But by 2005, development on GNU Arch itself had effectively stalled out, with various surviving siblings (ArX, Bazaar 1.x) heading off in different directions. In mid-August 2005, Tom Lord terminated development of Arch 2.0 (aka revc), recomending that users go forward with Bazaar 1.x, Robert Collins's fork of Tom Lord's original tla implementation.
Note
The baz (initially Bazaar) fork of tla AKA GNU Arch 1.0 should not be confused with bzr. Some time after tla development became stagnant, Collins's employer Canonical, Ltd. decided to terminate baz development and reassign the unqualified name “Bazaar” to Martin Pool's parallel effort in Python, bzr, which had until then been called Bazaar-NG or Bazaar 2.0.
ArX was a 2003 rewrite of Arch in C++ with a much-streamlined user interface. As of early 2008, this project appears moribund, with a last release in 2005 and only two registered developers.
Despite being hugely influential, neither Arch nor its direct descendants ever managed to look like more than laboratory experiments, and scored no design wins among major projects. The contrast with the Subversion team's effective positioning of its project and itself is extreme.
The monotone system was written by Graydon Hoare and first released in early 2003. It is thus roughly contemporary with darcs and Codeville, and all three of these systems influenced each other and were influenced by Arch during their early development. Later. monotone certainly influenced the design of Mercurial and probably of git as well.
Like Arch, monotone had a significant influence on the evolution of other 3G VCSes without acquiring a large following of its own, never scoring any major design wins. Serious performance problems were never entirely solved, and in 2007 monotone's author found himself recommending Mercurial to the Mozilla project as a better fit for their needs than monotone.
You will find in Appendix A a transcript of an IRC conversation I had with Graydon Hoare in which he argued convincingly that, though monotone is not presently competitive as a production system, there are important lessons still to be drawn from it.
BitKeeper is a merging, changeset-oriented, decentralized, commit-before-merge VCS designed by Larry McVoy. While the core concepts resembled those of Arch, they harked back to TeamWare, a VCS McVoy had previously designed and implemented at Sun Microsystems (Teamware 1.0 released in 1993). Development of BitKeeper began in 1997-1998.
Early on in BitKeeper's development McVoy decided that he wanted the Linux kernel as a reference account, modified the system to support the heavily decentralized and patch-oriented style of the Linux kernel developers, and pitched it heavily to Linus Torvalds and the open-source community in general.
In 2002 McVoy successfully persuaded Torvalds to adopt BitKeeper in the teeth of resistence from many kernel developers concerned about certain clauses in McVoy's proprietary license. On 1 July 2005, following a controversy about allegedly forbidden reverse engineering, McVoy withdrew the free-as-in-beer version the kernel developers had been relying upon. Torvalds promptly abandoned BitKeeper.
The most significant long-term result of this fiasco was probably to harden open-source community attitudes about licensing. It is now effectively impossible that the Linux or wider open-source communities will ever again accept a VCS with a closed-source license.
Despite this, McVoy has a strong claim to have originated several ideas that became central in later VCS designs, notably the representation of history as a changeset-based DAG, commit-before-merge operation, and the semantics of the associated push and pull operations. But the extent to which later VCS designers were directly influenced by BitKeeper is a messy and disputable question.
It is recorded that between 2002 and 2005 some open-source VCS projects (monotone, Arch, Codeville) had already decided that they needed to beat BitKeeper's feature set. After the fiasco, two others (Mercurial and git) were launched with the same objective by Linux kernel developers who had had extensive experience with BitKeeper.
However, the author of git (Linus Torvalds) later stated that he wanted git to be as unlike BitKeeper as possible, and other VCS architects later reported having been more influenced by Arch's and monotone's design ideas than by BitKeeper. As the withdrawal of the “community” version in 2005 left other VCS developers unable to examine or re-use the BitKeeper code, it is doubtful that the implementations of later VCSes owed a significant debt to BitKeeper.
These claims must be set against the fact that BitKeeper's documentation, terminology and basic operating model were common knowledge between 2002 and 2005, and the authors of later systems did not instantly lose that understanding when they were designing theirs.
It seems likely that later designs owe McVoy more than they admit, even if they can fairly be described as independent inventions.
Linus Torvalds invented git in 2005 as a way of recovering from the BitKeeper fiasco. Like other third-generation VCSes, it is merging rather than locking, snapshot-based, and decentralized.
The representations git uses to get these features are somewhat unusual, being strongly oriented towards tracking the content of an entire project rather than treating individual files as important containers. I'll have more to say about this in the Comparisons section.
In the following summary table, the last year given it is the year of release; if two years are given, the first is the year development began. Properties marked “-” are not really relevant in a VC with only file operations.
Table 1. VCS feature summary
| VCS | Year | Language | Verbs | Conflict resolution | Model | Units of operation | Commit atomicity | Data model | container identity |
|---|---|---|---|---|---|---|---|---|---|
| SCCS | 1972 | C | 13 | locking | local access | files | - | - | - |
| RCS | 1982? | C | 7 | locking | local access | files | - | - | - |
| DSEE/ClearCase | 1984 | C | >130 | locking | local access | files | - | - | - |
| CVS | 1984-1985 | C | 32 | merge-before-commit | centralized client-server | files | non-atomic | snapshot | no |
| Subversion (svn) | 2000-2004 | C | 32 | merge-before-commit or locking | centralized client-server | filesets | atomic | snapshot | no |
| BitKeeper | 1997-1999 | C | ? | commit-before-merge | decentralized | filesets | atomic | changeset | yes |
| Arch | 2001-2002 | sh, C | 107 | merge-before-commit | decentralized | filesets | atomic | changeset | yes |
| ArX | 2003 | C++ | 44 | merge-before-commit | decentralized | filesets | atomic | changeset | yes |
| Monotone (mtn) | 2003 | C++ | 63 | commit-before-merge | decentralized | filesets | atomic | changeset | yes |
The version of SCCS examined here is Jörg Schilling's Linux port of Solaris SCCS.
SCCS invented the concept of version control.
SCCS was locking, file-oriented, and centralized.
Registering a file into version control consisted of creating a corresponding master file to hold the revision history. Operations supported and still familiar included commit, checkout, dumping the revision log, branch creation, rollback (deleting the tip delta from the repository), and editing (actually, appending to) the change comment of a revision. Comments could be attached to revisions.
Original SCCS had no command to display diffs between revisions; an sccsdiff was added, in the style of more modern VCSes, in some later reimplementations.
SCCS did not represent the change history of a file as a tip copy minus deltas. Instead it used a representation later called a weave. An SCCS master contained every line ever committed to the repository, in order, with control information attached to each line describing the revisions in which it actually appeared. While slower for retrieving recent revisions than tip-minus-deltas, it did mean all revisions could be retrieved equally quickly.
SCCS keywords consisted of a percent sign, followed by an ASCII uppercase letter, followed by a percent sign. The percent signs were not retained to guard the keyword expansion, so it is not possible to tell which parts of the content are the results of such expansion. SCCS considered the complete absence of any such keywords in a master to be a (nonfatal) error.
$echo "This is a one-liner file." >foo.txt # Create our example file$admin -i foo.txt s.foo.txt # Register it into SCCS$get -e s.foo.txt # Check out a writable copy of foo.txtRetrieved: 1.1 new delta 1.2 1 linesecho "Adding a second line" >>foo.txt # Modify contents$delta s.foo.txt # Check in the changecomments?Example changeNo id keywords (cm7) 1.2 1 inserted 0 deleted 1 unchanged $get -e s.foo.txt # Check out an editable copy againRetrieved: 1.2 2 lines No id keywords (cm7) $unget s.foo.txt # Revert foo.txt to repository contents.1.2 $prs s.foo.txt # Display changelog of foo.txtD 1.2 07/12/26 10:24:16 esr 2 1 00001/00000/00001 MRs: COMMENTS: Example change D 1.1 07/12/26 10:21:05 esr 1 0 00001/00000/00000 MRs: COMMENTS: date and time created 07/12/26 10:21:05 by esr $admin -fb s.foo.txt # Enable branching in our sample master$get -b -e -r1.2 s.foo.txt # Get writeable copy, creating a branch1.1 new delta 1.2.1.1 2 lines
The admin, delta and get all remove the working-copy file after modifying the repository. (On the computers for which SCCS was originally written, disk space was expensive.)
Original SCCS expected to operate on master files created in the same directory as the workfile(s); this is the workflow shown in the example session above. More modern implementations generally use a wrapper script that shunts all master files to an SCCS subdirectory.
- admin
create and administer SCCS history files
- cdc
change the delta commentary of an SCCS delta
- comb
combine SCCS deltas
- delta
make a delta to an SCCS file
- get
retrieve a version of an SCCS file
- help
ask for help regarding SCCS error or warning messages
- prs
display selected portions of an SCCS history
- prt
display delta table information from an SCCS file
- rmdel
remove a delta from an SCCS file
- sact
editing activity status of an SCCS file
- unget
undo a previous get of an SCCS file
- val
validate an SCCS file
- what
extract SCCS version information from a file
Relative to many later VCSes, SCCS is a small and lightweight tool requiring only minimal setup. That would still give it a category of use cases if not for RCS.
Since nobody understood how ubiquitous computer networking was going to be, SCCS can't really be retrospectively criticized for its centralized model — it was a natural fit for a developers all sharing a single time-sharing machine.
Locking checkouts is also understandable in context; it was generally believed for more than a decade after SCCS was written that merging would frequently run into intractable cases and was therefore impractical. I can clearly recall my own surprise, as a veteran SCCS user, at learning that merging had proven practical in projects of more than trivial size.
But implementing only per-file deltas and not fileset operations from the beginning was an avoidable mistake, a large and damaging one from which the field would not fully recover for thirty years after SCCS was invented.
The dotted-pair VERSION.REVISION style of SCCS revision IDs was, in retrospect, an overcomplication. In theory the VERSION part was to be incremented to correspond to the numbering of a project's external versions; in practice, most projects never bothered, external release numbers were completely decoupled from revision IDs, and the VERSION field became just an irritating little bit of complexity overhead.
SCCS's command-line interface was deeply ugly and rather confusing even to experienced users. [1] Modern implementations such as GNU SCCS and the Berkeley version it was derived from feature a wrapper script that hides some of the more rebarbative aspects of the interface.
No support for binary files. If you were to check a binary file in, it could very well be corrupted on checkout by SCCS keyword expansions. While there is an administrative option to suppress these, counting on any SCCS implementation to handle binary “lines” of potentially arbitrary length would be unwise.
The author of SCCS described it in The Source Code Control System (IEEE Transactions on Software Engineering SE-1:4, Dec. 1975, pages 364-370).
While SCCS's limitations were well-known in its day, I have been unable to find any criticism of it more analytical than Ken Thompson's parody of a contemporary advertisment for an insecticide called the Roach Motel: “SCCS is the source-code motel — your code checks in, but it never checks out.”
The weave representation, abandoned for many years in favor of RCS-style delta sequences, has recently experienced a bit of a renaissance among designers of third-generation VCSes, and is actually used in BitKeeper, Codeville and bzr. While originally a performance hack, it turns out to have some useful properties for computing merges rapidly (on files that are mostly line-oriented text, including source code).
This analysis describes RCS 5.7.
RCS was locking, file-oriented, and centralized.
RCS pioneered the technique of storing file history as a tip copy minus deltas; this made it much faster than SCCS for retrieving recent revisions, though slower for retrieving old ones.
RCS's main user-visible innovation were (1) supporting tags, symbolic names for revisions, and (2) the introduction of an extremely clumsy but usable merge command.
$echo "This is a one-liner file." >foo.txt # Create our example file$ci -u foo.txt # Register it into RCSRCS/foo.txt,v <-- foo.txt enter description, terminated with single '.' or end of file: NOTE: This is NOT the log message! >> a boring log message >> . initial revision: 1.1 done $co -l s.foo.txt # Check out a writable copy of foo.txtRCS/foo.txt,v --> foo.txt revision 1.1 (locked) doneecho "Adding a second line" >>foo.txt # Modify contents$ci -u foo.txtRCS/foo.sh,v <-- foo.sh new revision: 1.2; previous revision: 1.1 enter log message, terminated with single '.' or end of file: >> Example change. >> . done $rcs -nTAG_ME:1.2 foo.txt # Give r1.2 the symbolic name TAG.MERCS file: RCS/foo.txt,v done $rlog foo.txt # Display the revision logRCS file: RCS/foo.txt,v Working file: foo.txt head: 1.2 branch: locks: strict access list: symbolic names: TAG_ME: 1.2 keyword substitution: kv total revisions: 2; selected revisions: 2 description: a boring log message ---------------------------- revision 1.2 date: 2007/12/26 16:00:42; author: esr; state: Exp; lines: +1 -0 Example change. ---------------------------- revision 1.1 date: 2007/12/26 15:59:40; author: esr; state: Exp; Initial revision
- ci
check in RCS revisions
- co
check out RCS revisions
- ident
identify RCS keyword strings in files
- rcsclean
clean up working files
- rcsdiff
compare RCS revisions
- rcslog
print log messages and other information about RCS files
- rcsmerge
merge RCS revisions
RCS was intended to be better at doing the same things SCCS did. While RCS succeeded in that aim, the functional differences are subtle. The most conspicuous one was probably better performance.
RCS's command-line interface, while not pretty, was simpler and distinctly less ugly than SCCS's.
RCS master files were named by suffixing the name of their source with “,v”. While peculiar, this was less odd than SCCS's is of an “s.” prefix.
RCS keywords consisted of a dollar sign, followed by one of a well-defined inventory of key strings such as “Id” or “Rev”, followed by a dollar sign. uppercase letter, followed by a percent sign. The dollar signs and the key string are retained in the keyword expansion, with subtituted text inserted following a colon just before the substituted text. This was an improvement on SCCS keywords because it made it possible to tell which portions of a working file are expanded from keywords.
RCS, emulating a weakness in SCCS, conspicuously failed to invent fileset operations.
Recent versions of RCS support binary files, but you have to be careful to suppress keyword expansion. There is an administrative command to do this.
The author's description of RCS, from 1985, is RCS: A System for Version Control.
I have been unable to find any analytical criticism of RCS.
RCS invented the technique of describing a file's revision history as a tip copy and a sequence of backwards deltas. This supplanted SCCS's weave representation as the method used in most later VCSes.
RCS's terminology (“revision” rather than “version”, “checkout” rather than “get”, “checkin” rather than “delta”, “master” rather than “history file”, and more) replaced SCCS's original terms so completely that recent descriptions of SCCS itself are written in RCS terminology. Second and third-generation VCSes inherited and extended this vocabulary.
Later systems that supported keyword expansion retained the RCS set of keywords, with minor variations.
RCS by itself still has a use case in single-file, single-developer projects; it's about the simplest possible way to store revision history without keeping multiple copies of a file.
RCS as a component is still in sufficiently wide use in other VCSes today, more than two decades after Tichy's paper, to suggest that within its limited objectives the design and implementation were basically sound.
One interesting present-day use of RCS is a revision store for wiki engines. It fits there; filesets and changesets are not necessary (the unit you want to save is always a single page) and speed is paramount.
This description has been extracted and interpreted from public documents describing DSEE and ClearCase.
DSEE/ClearCase is locking, file-oriented, and centralized. General client/server operation over TCP/IP was not supported, in DSEE it was designed to be used with network file systems including NFS, DECnet (now obsolete) and Apollo's own Domain/PCI (now obsolete). Recent versions of ClearCase add a Web interface. ClearCase supports managing binary files.
DSEE/ClearCase includes configuration-management features which are beyond the scope of this survey. The Wikipedia article on Rational ClearCase pesents (at least at time of writing in early 2008) a good overview of these features.
The most interesting feature of DSEE/ClearCase as a VCS is that its repositories are not databases managed by a userspace program. Instead, a repo is a special filesystem in which the pathnames encode information about revision levels and branch names. The underlying representation uses RCS-like deltas (and, at least in ClearCase, an equivalent of xdeltas on binary files) for space efficiency, but that implementation tactic is completely hidden from the user.
This tutorial, Clearcase Client Commands, gives a good feel for the style and many of the details of the ClearCase interface.
Because a DSEE/ClearCase repository looks like a filesystem to serspace programs, normal Unix tools can work on things in the repository without requiring an explicit checkout operation.
Implementation of DSEE/ClearCase operations in a kernel-level filesystem module gives stronger atomicity guarantees than a userspace tool could offer. We may also safely suppose there are significant performance gains from this approach (and hardware was much slower in DSEE's heyday than today, so this mattered much more at the time the system was designed).
DSEE already supported history-sensitive merging in 1991. While the utility of this feature was badly hindered by the file granularity of DSEE operations, it is better than competing systems (notably CVS) managed to do for years afterwards.
DSEE/ClearCase is locking-based rather than merging-based (DSEE literature used the term "reserved"). There was no representation of changesets; commits were, and remain in ClearCase, strictly file-oriented.
The Rational ClearCase command interface is extremely complex and baroque. While it is possible that earlier (DSEE and Atria ClearCase) versions were simpler, the underlying architecture makes this seem unlikely.
The kernel-level implementation of DSEE/ClearCase repositories makes the system difficult to port. (There is a Linux port, however.)
Most of the material about architecture is drawn from this 1991 article: DSEE: a software configuration management tool - Domain Software Engineering Environment.
This discussion thread seems representative of the criticisms and defenses of ClearCase.
DSEE/ClearCase has no obvious lessons for today's VCSes, except perhaps that many corporate customers value CM features so highly that in order to get or keep them they will tolerate a VCS engine that is very deficient by modern standards.
DSEE was about as advanced as one could get without making the conceptual leap to a merging-oriented system, but that model is now long obsolete.
While the repository-as-filesystem model had attractive features, it had the effect of bolting DSEE firmly to a file-oriented model and an inability to represesent or operate on changesets. This defect still afflicts its descendant ClearCase.
Neither system can be recommended unless at this late date unless their specific CM features (not covered here) seem overwhelmingly important.
This analysis describes CVS version 1.11.22.
CVS is file-oriented and centralized. The default conflict-resolution model is merge-before-commit. It is possible to make CVS operate in a locking mode, but this is done so rarely that most CVS users are unaware of the capability.
CVS introduced a notion of “modules”: subdirectories of a CVS repository that can be checked out individually and worked with, without the necessity of copying out the entire repository. Typically each separate project on a CVS server has its own module.
CVS was originally written as a collection of wrapper scripts around RCS. What these scripts did, in effect, was map from CVS revision numbers global in each module to a tuple of RCS revision numbers not normally visible to the user, one per CVS-controlled file in the module. The mapping was contained in administrative files but ordinarily visible to the user. This organization was retained when the upper layer was rewritten in C and as the RCS layer (already in C) was gradually extended and customized for CVS's needs.
The CVS user interface creates the appearance of fileset operations. That is, it is possible to do a checkin on a group of multiple files with the same change comment. However, what actually happens is that the upper layer does a sequence of checkins on each file in the group; the comment is replicated into an individual RCS master for each file.
Though CVS has fileset operations, CVS's multi-file commits are not true changesets because they are not atomically applied and do not carry information about operations on the file tree (adds, deletes, and renames). Indeed, CVS has no actual support for renames at all. Users have to choose between either a delete-add sequence that loses the file's change history, or moving the RCS master in the repo. Moving the master won't work without a shell account on the host machine.
It is possible to define CVS branches. To accomplish this, module-wide branch numbers have to be mapped to (often different) hidden branch IDs in each individual RCS master.
CVS also supports repository-wide tagging. That is, you can associate a symbolic name with a CVS revision ID and use that symbolic name to retrieve or refer to the revision.
It is possible to put hook scripts in a CVS repository that will fire at various interesting times — notably before each commit, or after. Hook scripts can be used for many purposes, including enforcing fine-grained access control and sending automated commit notifications to mailing lists, bug trackers, or even IRC channels.
This session is deliberately a bit unusual, in two ways.
Normally one would start working with a CVS project by doing a checkout from an existing repository, probably on a remote machine. I have chosen instead to show how a project repository is created from scratch, and then show a local checkout and subsequent operations. A more normal (remote) checkout would differ in having a @ and hostname in its -d option.
The second slightly unusual thing is the use of the -m option to
specify change messages. Without those, CVS would try to figure out
what editor I like (from the environment variables
$CVSEDITOR and $EDITOR) and run that
on a temporary file, taking its change comment from the state of the
file when I exit. But this is difficult to show in a session
transcript, so I used -m to prevent it. With neither -m nor an editor
environment variable handy, CVS will prompt for input line-by-line in
the style of RCS.
In the transcript below, some relative paths from
scratch were absolute paths in the
actual machine output.
$mkdir scratch # Create a repository directory$CVSROOT=$PWD/scratch # Define the repository root for later commands$export CVSROOT$cvs init # Create an empty repository at $CVSROOT# Creating a new module (project subdirectory) is an awkward process # that involves hand-editing the repository's administration files. # We start by checking out the repository modules file. # $cvs checkout CVSROOT/modulesU CVSROOT/modules $echo "example example" >>CVSROOT/modules$cd CVSROOT$cvs commit -m "Added the example module." modulesscratch/CVSROOT/modules,v <-- modules new revision: 1.2; previous revision: 1.1 cvs commit: Rebuilding administrative file database $cd ..$cvs release -d CVSROOTYou have [0] altered files in this repository. Are you sure you want to release (and delete) directory `CVSROOT': yes # Make the directory structure for the repo # $mkdir scratch/example# Now we check out a working copy of the new module. # A more typical invocation of co to fetch a project from a # remote repository would look like this: # # cvs -d:ext:esr@cvs.savannah.gnu.org:/sources/emacs co emacs # # The -d option is equivalent to setting the CVSROOT environment # variable. In this example it specifies my username on savannah.org # and a path to a CVS repository there. # $cvs co examplecvs checkout: Updating example # Enter the project directory, and copy our sample file there # $cd example$echo "This is a one-liner file." >foo.txt # Create our example file# Add it. This only schedules copying the data into the repository; # it won't be actually done until the next commit. # $cvs add foo.txtcvs add: scheduling file `foo.txt' for addition cvs add: use `cvs commit' to add this file permanently # Commit the addition to put the file in the repository # $cvs commit -m "Commit the add."cvs commit: Examining . scratch/example/foo.txt,v <-- foo.txt initial revision: 1.1 # Examine the status of the repository # $cvs status=================================================================== File: foo.txt Status: Up-to-date Working revision: 1.1 2007-12-27 12:52:26 -0500 Repository revision: 1.1 scratch/example/foo.txt,v Commit Identifier: uZMQoP57P4eyx6Ls Sticky Tag: (none) Sticky Date: (none) Sticky Options: (none) # Modify the file contents # $echo "Adding a second line" >>foo.txt# Note that the status command now reports this file as modified. # $cvs status: Examining .=================================================================== File: foo.txt Status: Locally Modified Working revision: 1.1 2007-12-27 12:52:26 -0500 Repository revision: 1.1 scratch/example/foo.txt,v Commit Identifier: uZMQoP57P4eyx6Ls Sticky Tag: (none) Sticky Date: (none) Sticky Options: (none) # We can examine the difference between the working file # and the repository copy. # $cvs diffcvs diff: Diffing . Index: foo.txt =================================================================== RCS file: /home/esr/WWW/writings/version-control/scratch/example/foo.txt,v retrieving revision 1.1 diff -r1.1 foo.txt 1a2 > Adding a second line # Now we commit the change # $cvs commit -m "Second commit"cvs commit: Examining . scratch/example/foo.txt,v <-- foo.txt new revision: 1.2; previous revision: 1.1 # Add a tag # $cvs tag TAG_MEcvs tag: Tagging . T foo.txt # Dump the revision history # $cvs logcvs log: Logging . RCS file: scratch/example/foo.txt,v Working file: foo.txt head: 1.2 branch: locks: strict access list: symbolic names: TAG_ME: 1.2 keyword substitution: kv total revisions: 2; selected revisions: 2 description: ---------------------------- revision 1.2 date: 2007-12-27 23:34:36 -0500; author: esr; state: Exp; lines: +1 -0; commitid: oY0RLt7ljRNIw9Ls; Second commit ---------------------------- revision 1.1 date: 2007-12-27 23:33:41 -0500; author: esr; state: Exp; commitid: bQ9tRHF6ejqpw9Ls; Commit the add. =============================================================================
- add
Add a new file/directory to the repository
- admin
Administration front end for rcs
- annotate
Show last revision where each line was modified
- checkout
Checkout sources for editing
- commit
Check files into the repository
- diff
Show differences between revisions
- edit
Get ready to edit a watched file
- editors
See who is editing a watched file
- export
Export sources from CVS, similar to checkout
- history
Show repository access history
- import
Import sources into CVS, using vendor branches
- init
Create a CVS repository if it doesn't exist
- log
Print out history information for files
- login
Prompt for password for authenticating server
- logout
Removes entry in
.cvspassfor remote repository- ls
List files available from CVS
- pserver
Password server mode
- rannotate
Show last revision where each line of module was modified
- rdiff
Create 'patch' format diffs between releases
- release
Indicate that a module is no longer in use
- remove
Remove an entry from the repository
- rlog
Print out history information for a module
- rls
List files in a module
- rtag
Add a symbolic tag to a module
- server
Server mode
- status
Display status information on checked out files
- tag
Add a symbolic tag to checked out version of files
- unedit
Undo an edit command
- update
Bring work tree in sync with repository
- version
Show current CVS version(s)
- watch
Set watches
- watchers
See who is watching a file
CVS was the first (and for some years the only) VCS that could be used in a client-server mode across a network.
CVS showed that resolving conficts by merging rather than requiring locking was actually practical.
The one-central-repository model forecloses disconnected operation.
The mapping between module-wide revision numbers and the semi-hidden tuples of RCS revision numbers they correspond to is tricky to maintain and fragile, especially when multiple attempts to modify the mapping are going on at the same time. Additions, deletions, and branching are particular danger points.
CVS has no integrity checking at either upper or lower levels. Thus, when the mapping logic breaks down, it produces not just repository corruption but undetectable repository corruption.
Commits are non-atomic; it is possible to successfully commit part of an intended change and then be blocked by a conflict. (In some later versions, commits within a single directory are atomic but commits across more than one directory may not be.) Though this does not corrupt the repository, it can easily leave the code in a state of inconsistency. Suppose, for example, that the commit is indended to delete the definition of and all calls to a particular function; if it is interrupted by a conflict in a calling file after the definition has been deleted, one or motre references will be left dangling and the build of the project will break.
Tags and branches are expensive: they require writing to every RCS master in the repository. The user interface of the branching facilities is tricky.
There is no merge tracking. That is, branches don't record what changesets from other branches have been merged into them and should not be re-tried on the next merge. This makes it difficult to maintain parallel lines of development (as in, stable and development branches) without either constant merge conflicts, or a lot of annoying handwork, or both. In general, the effect is to seriously reduce the usefulness of branching.
There is no container identity. Directories are not versioned, but are rather created as needed on each checkout. This means both that CVS does not preserve positions and ownership, and that you cannot have an empty directory as part of a version-controlled file tree.
CVS inherited RCS's marginal support for binary files. It, also, has an administrative command to disable keyword expansion.
CVS's messy architecture begat a messy and difficult implementation. Because the internals are hard to understand, it has only been lightly and intermittently maintained for much of its history. The quality of the resulting code is dubious.
Dick Grune described the original CVS in an unpublished 1986 paper. Brian Berliner described the C rewrite in a 1990 paper CVS II: Parallelizing Software Development. A 2006 interview focuses on the differences between the Grune and Berliner implementations.
I have been unable to find any analytical critiques of CVS on the Web. This is rather surprising, as developers have been griping about its well-known limitations for more than a decade.
CVS's client-server model has been replaced in third generation systems (by push/pull between peer repositories) and most of what was distinctive about CVS went away along with that. But two conspicuous features of CVS have persisted in later systems: merge-based conflict resolution and the style of the CVS command-line interface.
SCCS and RCS presented themselves as collections of smaller tools, each with its own name and idiosyncratic collection of options. Almost all CVS commands, on the other hand, are invoked through a single cvs command, typically with a following verb such as “add”, “commit”, or “log”, and with the verb typically followed by a list of files to act on.
This interface style proved so well suited to expressing VCS operations that most later systems adopted it. Indeed, it is often possible to compose basic commands in Subversion or a third-generation VCS simply by typing the CVS command with the initial “cvs” replaced by the conventional short name of the newer system.
This analysis describes SVN version 1.4.
At the top of the Subversion project's http://subversion.tigris.org/, it says “The goal of the Subversion project is to build a version control system that is a compelling replacement for CVS in the open source community.”. Subversion remsembles CVS wherever doing so would not perpetuate a bug, even down to details like mimicking CVS/RCS keyword expansion.
Subversion is, like CVS, merging-based, snapshot-based, and centralized. It is possible to make it operate in a locking mode; the Subversion developers even claim this choice is popular outside the open-source community.
Files under Subversion do not have individual revision numbers; rather, the revision level is a property of the entire project. Each commit, which may include a comment and changes to any number of files, increments the revision level of the entire project. Revision numbers are integers starting from 1.
Subversion includes a hook-script facility like that of CVS, but with more and better-documented hooks.
Each Subversion branch can be viewed as a sequence of changesets, with revision numbers actually being changeset IDs. Internally, however, Subversion is a snapshot-based system and does not do container identity.
Conventionally, every project has a main branch called
“trunk”. If you check out a project named
“example”, the project files will normally
actually live under example/trunk. Other
subdirectories, if any, will contain branches and tags.
Branching is implemented as a sort of lazy directory copy. A branch is a set of links back to the branch (or trunk) it was copied from; when a file is modified in the branch its link is snapped and replaced with the modified version. This makes branching cheap, though it tends to obscure where the branch point was. The revision ID of branch point is not, as it is in SCCS and RCS, embedded in the revision ID of all its descendents; instead you have to look at the changelog if you want to determine it.
Subversion doesn't have tags, in the RCS/CVS sense of a
symbolic name for a revision level. Instead, Subversion encourages
you to use cheap branching as tagging. Conventionally the branches
that are tags live under a peer directory of “trunk”
named “tags”; you might, for example, have a directory.
named example/tags/release-1.0.
This way of handling tags has two perhaps surprising consequences. One is that tagged snapshots can be modified after tagging; project administrators who went to prevent this need to configure hook scripts to block commits to the tags directory. The other is that when more than one branch is being modified, the revision numbers of adjacent snapshots may differ by more than 1.
Every subdirectory of a Subversion working copy behaves like a CVS module; it can be checked out and/or updated independently of its peers. In particular, it's possible to check out and work with a project's trunk directory without ever copying or caring about the peer tags and branches directories.
As with the CVS session, I use -m here to specify commit messages rather than having SVN run an editor to collect them.
echo "This is a one-liner file." >foo.txt # Create our example file $svnadmin create SVN # Create empty repo in subdirectory SVN$svn checkout file://$PWD/SVN . # Check out a working copy here.Checked out revision 0. $svn add foo.txt # Schedule foo.txt to be added to the repoA foo.txt $svn -m "First commit" commit # Commit the additionAdding foo.txt Transmitting file data . Committed revision 1. $svn status # No output means no local modifications$echo "Adding a second line" >>foo.txt$svn status # Now we see that foo.txt is locally modifiedM foo.txt $svn diff # We examine the differencesIndex: foo.txt =================================================================== --- foo.txt (revision 1) +++ foo.txt (working copy) @@ -1 +1,2 @@ This is a one-liner file. +Adding a second line $svn commit -m "Second commit" # We commit the changeSending foo.txt Transmitting file data . Committed revision 2. $svn log foo.txt # We examine the revision log------------------------------------------------------------------------ r2 | esr | 2007-12-28 06:37:46 -0500 (Fri, 28 Dec 2007) | 1 line Second commit ------------------------------------------------------------------------ r1 | esr | 2007-12-28 06:12:42 -0500 (Fri, 28 Dec 2007) | 1 line First commit ------------------------------------------------------------------------ $svn rename foo.txt bar.txt # This is what a rename looks likeA bar.txt D foo.txt $svn commit -m "Example rename" # Commit the rename so it actually happensAdding bar.txt Deleting foo.txt Committed revision 3. $svn log # History is preserved across the rename------------------------------------------------------------------------ esr@snark:~/WWW/writings/version-control$svn log bar.txt------------------------------------------------------------------------ r3 | esr | 2007-12-28 06:48:40 -0500 (Fri, 28 Dec 2007) | 1 line Example rename ------------------------------------------------------------------------ r2 | esr | 2007-12-28 06:37:46 -0500 (Fri, 28 Dec 2007) | 1 line Second commit ------------------------------------------------------------------------ r1 | esr | 2007-12-28 06:12:42 -0500 (Fri, 28 Dec 2007) | 1 line First commit ------------------------------------------------------------------------
Terms in parentheses are command aliases.
- add
Put files and directories under version control
- blame (praise, annotate, ann)
show specified files or URLs with revision and author information in-line.
- cat
Output the content of specified files or URLs
- checkout (co)
Check out a working copy from a repository.
- cleanup
Recursively clean up the working copy, removing locks, resuming unfinished operations, etc.
- commit (ci)
Send changes from your working copy to the repository.
- copy (cp)
Duplicate something in working copy or repository, remembering history.
- delete (del, remove, rm)
Remove files and directories from version control.
- diff (di)
Display the differences between two revisions or paths.
- export
Create an unversioned copy of a tree.
- help (?, h)
Describe the usage of this program or its subcommands.
- import
Commit an unversioned file or tree into the repository.
- info
Display information about a local or remote item.
- list (ls)
List directory entries in the repository.
- lock
Lock working copy paths or URLs in the repository, so that no other user can commit changes to them.
- log
Show the log messages for a set of revision(s) and/or file(s).
- merge
Apply the differences between two sources to a working copy path.
- mkdir
Create a new directory under version control.
- move (mv, rename, ren)
Move and/or rename something in working copy or repository.
- propdel (pdel, pd)
Remove a property from files, dirs, or revisions.
- propedit (pedit, pe)
Edit a property with an external editor.
- propget (pget, pg)
Print the value of a property on files, dirs, or revisions.
- proplist (plist, pl)
List all properties on files, dirs, or revisions.
- propset (pset, ps)
Set the value of a property on files, dirs, or revisions.
- resolved
Remove 'conflicted' state on working copy files or directories.
- revert
Restore pristine working copy file (undo most local edits).
- status (stat, st)
Print the status of working copy files and directories.
- switch (sw)
Update the working copy to a different URL.
- unlock
Unlock working copy paths or URLs.
- update (up)
Bring changes from the repository into the working copy.
Commits are fileset-based and atomic. The conflict-resolution model is merge-before-commit. Binary files are supported. File-tree operations (add, delete, rename) are supported — not perfectly, but with dramatically better behavior than CVS.
As noted in the history section, Subversion's combination of a conservative, simple, CVS-like interface with atomic fileset commits has proven attractive for many projects. The relatively high quality of its documentation has helped, as well.
Subversion has a well-designed and documented library API that makes it relatively easy to write custom clients. This has made projects like SVK possible.
The Subversion development team has an (earned) reputation for talent and maturity. It also has unusual depth on the bench, being less dependent on one or two star programmers than is true for many younger projects. These qualities contribute to the perception that Subversion is a safe, solid choice.
The one-central-repository model forecloses disconnected operation.
While Subversion's performance is generally considered quite acceptable even for large projects, it is not consistent. Implementation problems in the fairly heavyweight database underneath the hood can sometimes make even small operations inexplicably laggy.
Subversion's handling of file moves and renames is a big improvement on CVS's, but it remains flawed. They're implemented as a copy of both the file and its history followed by a delete, rather than an a single atomic rename operation. While this works satisfactorily for projects with a linear version history, there are branch-merging situations where it can lose history information.
Additionally, the output report of Subversion's command-line “rename” tool makes the copy and delete visible to users, who tend to find the split confusing and the magic preservation of history through the split a bit counterintuitive.
A more fundamental weakness in Subversion is the same absence of merge tracking that so reduced the usefulness of CVS branches. The Subversion developers have plans to implement merge tracking that have not been fully implemented or shipped at time of writing in early 2008.
Subversion's handling of tagging has been controversial. Many critics, including some Subversion developers, have argued that writeable directory copies violate users' intuitions about how tags should behave, and that Subversion should instead have an RCS/CVS-like capability for referring to revision numbers by symbolic names. This is, however, generally considered a minor issue.
The Subversion developers have never written down in any one place a detailed apologia on their design decisions and architecture. Most of what is publicly known about the design has emerged from their responses to critiques leveled by authors of other systems.
Tom Lord, the author of Arch, wrote a critique in 2003 called Diagnosing SVN which subsequently became quite well known. With Greg Hudson's response, Undiagnosing SVN, it does a pretty good job of capturing several of the standard criticisms of Subversion and the Subversion team's defense of their choices. At the core of it was an argument over the relative merits of snapshots vs. changesets.
A more recent and extreme critique came from Linus Torvalds's imfamous mid-2007 Google Tech Talk on git. While a lot of his anti-SVN diatribe can fairly be dismissed as rude flamage by someone who simply didn't care about the problems SVN was aimed at solving, Linus was dead on target when he accused the SVN devs of investing way too much on cheap branching and not nearly enough on the support for history-aware merging that is needed to make branching really useful.
Subversion architect Karl Fogel's indirect response explains that the Subversion developers focus, as they always have, on the problems they can see in immediately front of them and the points of pain that their users report. Fogel hints that the Subversion team sees a future for Subversion primarily in the sort of closed-source development shop that thinks locking checkouts are a feature, not in an open-source community rapidly going in the opposite direction by adopting third-generation VCSes.
Subversion hammered home the importance of atomic commits of entire filesets, as opposed to single file deltas. While some previous VCSes had this feature, none of those succeeded in convincing the vast mass of CVS users that it was a compelling reason to change systems. All later designs have absorbed this lesson and built on it.
The architects of Subversion discarded the dotted-pair revision IDs of SCCS, RCS, and CVS; instead, commits are simple integer sequence numbers. This was a valuable simplification that later systems emulated.
Subversion's cleaner, lighter adaptation of the CVS command-line interface set a pattern for later systems, many of which which have very sensibly emulated as much of it as they could given the differences between centralized and decentralized operation (even to, for example, using the same letter flags in their status reports). The command sets of Mercurial and bzr, in particular, are surprisingly close to Subversion's.
This analysis describes GNU Arch (“tla”) version 1.3.5.
VCSes implementing the Arch specification are decentralized and has a changesets-based data model with container identity.
More specifically, the Arch variants were the first VCSes to be explicitly, publicly based on the theory that repository history should be modeled as a graph of changesets rather than a graph of snapshots. (BitKeeper may have been had priority on these ideas, but, as I have previously noted, its influence is disputable.)
This sample session is incomplete. It fell afoul of a bug in of which the author said “Perhaps it's bitrot.”. I have included it anyway to illustrate the style of the interface.
# Arch wants to know who I am before it will deal with me. # This only need to be done once, not every time I start a session. # $tla my-id "Eric S. Raymond <esr@thyrsus.com>"# Create a directory in which to store archives: # $mkdir {archives}# Create a new archive, specifying its name and subdirectory # $tla make-archive esr@thyrsus.com--2007-example {archives}/2007-example# Make this my default archive -- cuts down on command verbosity later # $tla my-default-archive esr@thyrsus.com--2007-example# Arch commands normally don't emit any messages on success, # But there are a couple of commands we can use to check that # Arch hasn't done nothing. # $tla archivesesr@thyrsus.com--2007-example {archives}/2007-example $tla whereis-archive esr@thyrsus.com--2007-example{archives}/2007-example # An archive is not a project, exactly. Arch views the archive data # as a collection of 'lines of development' or 'branches'. Each branch # is identified by a category, a branch name, and a number, which the Arch # documentation peculiarly calls a 'version number' in spite of the # fact that it has nothing to do with the normal VCS concept of a # version number. The category name is what most closely corresponds # to the conventional notion of a 'project'. We'll create a branch # with category 'hello', name 'trunk', and version number 0.1. # $tla archive-setup example--trunk--0.1* creating version esr@thyrsus.com--2007-example/example--trunk--0.1 # The archive has now invisibly grown a couple of more layers of structure. $tla categoriesexample $tla branches exampleexample--trunk $tla versions example--trunkexample--trunk--0.1 # Next we tell Arch to set up a working directory, telling Arch what # branch we want to associate it with. # $tla init-tree example--trunk--0.1# Now we'll actually create our standard example file # $echo "This is a one-liner file." >foo.txt# And add it... # $tla add foo.txt# Before we can commit the add, we have to create a log message. # The way Arch wants us to do this is to create a logfile, # just an ordinary file in the working directory but with a # special name (below, the directory part is trimmed for brevity). # $tla make-log++log.example--trunk--0.1--esr@thyrsus.com--2007-example # This log file has some fields in it that Arch expects to interpret. # They start out empty: # $cat ++log.example--trunk--0.1--esr@thyrsus.com--2007-exampleSummary: Keywords: # Arch expects us to edit this file. We'll do that, leaving it in this state: # $cat ++log.example--trunk--0.1--esr@thyrsus.com--2007-exampleSummary: First commit. Keywords: This is a dummy commit message. # At this point it should be possible to commit the change with # 'tla commit'. However, this operation fails. The author of Arch # said "Perhaps it's bit rot." suggested I run a symbolic debugger # on the tla, and described tla as "largely a long-dead project."
Command summaries have been left unsorted in the sequence tla help emits them and grouped into subsections corresponding to sections in the tla help architecture. The command set is too difficult to understand otherwise.
- my-id
print or change your id
- my-default-archive
print or change your default archive
- register-archive
change an archive location registration
- archive-register
(alias for register-archive)
- whereis-archive
print an archive location registration
- archives
report registered archives and their locations
- init-tree
initialize a new project tree
- tree-root
find and print the root of a project tree
- tree-version
print the default version for a project tree
- tree-id
Print the tree identifier for a project tree
- tree-revision
Print the tree identifier for a project tree
- set-tree-version
set the default version for a project tree
- undo
undo and save changes in a project tree
- redo
redo changes in project tree
- changes
report about local changes in a project tree
- file-diff
show local changes to a file
- diff
report about local changes in a project tree
- export
export all or some of a tree revision
- inventory
inventory a source tree
- tree-lint
(alias for lint)
- lint
audit a source tree
- id
report the inventory id for a file
- id-tagging-method
print or change a project tree id tagging method
- add
(alias for add-id)
- add-id
add an explicit inventory id
- delete-id
remove an explicit inventory id
- move-id
move an explicit inventory id
- touch
add an explicit inventory id, touching the file.
- rm
remove a file (or dir, or symlink) and its explicit inventory tag
- mv
move a file (or dir, or symlink) and its explicit inventory tag
- explicit-default
print or modify default ids
- default-id
(alias for explicit-default)
- id-tagging-defaults
print the default =tagging-method contents
- changeset
compute a whole-tree changeset
- mkpatch
(alias for changeset)
- apply-changeset
apply a whole-tree changeset
- dopatch
(alias for apply-changeset)
- show-changeset
generate a report from a changeset
- make-archive
create a new archive directory
- archive-create
(alias for make-archive)
- archive-setup
create new categories, branches and versions
- make-category
create a new archive category
- make-branch
create a new archive branch
- make-version
create a new archive version
- import
archive a full-source base-0 revision
- commit
archive a changeset-based revision
- get
construct a project tree for a revision
- get-changeset
retrieve a changeset from an archive
- lock-revision
lock (or unlock) an archive revision
- archive-mirror
update an archive mirror
- abrowse
print an outline describing archive contents
- rbrowse
print an outline describing an archive's contents
- categories
list the categories in an archive
- branches
list the branches in an archive category
- versions
list the versions in an archive branch
- revisions
list the revisions in an archive version
- ancestry
display the ancestory of a revision
- ancestry-graph
display the ancestory of a revision
- cat-archive-log
print the contents of an archived log entry
- cacherev
cache a full source tree in an archive
- cachedrevs
list cached revisions in an archive
- uncacherev
remove a cached full source tree from an archive
- archive-meta-info
report meta-info from an archive
- archive-snapshot
update an archive snapshot
- archive-version
list the archive-version in an archive
- archive-fixup
fix ancillary files in an archive
- make-log
initialize a new log file entry
- log-versions
list patch log versions in a project tree
- add-log-version
add a patch log version to a project tree
- remove-log-version
remove a version's patch log from a project tree
- logs
list patch logs for a version in a project tree
- cat-log
print the contents of a project tree log entry
- changelog
generate a ChangeLog from a patch log
- log-for-merge
generate a log entry body for a merge
- merges
report where two branches have been merged
- new-merges
list tree patches new to a version
- build-config
instantiate a multi-project config
- cat-config
output information about a multi-project config
- tag
create a continuation revision
- branch
create a continuation revision
- switch
change the working trees version
- update
update a project tree
- replay
apply revision changesets to a project tree
- star-merge
merge mutually merged branches
- apply-delta
compute a changeset between any two trees or revisions and apply it to a project tree
- missing
print patches missing from a project tree
- join-branch
add a version as an ancestor of a project tree
- sync-tree
unify a project tree's patch-log with a given revision
- delta
compute a changeset (or diff) between any two trees or revisions
- changes
report about local changes in a project tree
- file-diff
show local changes to a file
- file-find
find given version of file
- pristines
list pristine trees in a project tree
- lock-pristine
lock (or unlock) a pristine tree
- add-pristine
ensure that a project tree has a particular pristine revision
- find-pristine
find and print the path to a pristine revision
- my-revision-library
print or change your revision library path
- library-dir
(alias for my-revision-library)
- library-config
configure parameters of a revision library
- library-find
find and print the location of a revision in the revision library
- library-add
add a revision to the revision library
- library-remove
remove a revision from the revision library
- library-archives
list the archives in your revision library
- library-categories
list the categories in your revision library
- library-branches
list the branches in a library category
- library-versions
list the versions in a library branch
- library-revisions
list the revisions in a library version
- library-log
output a log message from the revision library
- library-file
find a file in a revision library
Arch was the first VCS to be explicitly based on a graph of changesets rather than snapshots. It also pioneered container identity tracking.
The interface of Tom Lord's original larch, and of later close variants such as GNU arch/tla, is forbiddingly complex. It requires lots of fussy multiple-command rituals for operations conducted with single commands on other VCSes of comparable power. Worse, it is both these things and poorly documented as well. The naming conventions for working-copy special files are strange, ugly, and obtrusive. Taken as a whole, the surface features of Arch seem successfully designed to frighten people away.
The larch/tla user interface truthfully reflects a degree of complexity in the underlying architecture that was, in light of later designs, unnecessary. While the designers of various daughter implementations strove manfully to simplify the interface, there was little they could do about the underlying complexity.
Arch has a merge-before-commit model. While this looked natural at the time it was invented (the possibility of commit-before-merge not yet having been understood), later designs have shown that this choice robs a changeset-based VCS of much of the power and flexibility afforded by a commit-before-merge model.
Tom Lord explained the underlying theory of Arch as a browser and editor of changeset graphs in a December 2002 essay on the Subversion mail list.
In 2008 Arch probably no longer has significant lessons to teach beyond the (very large and important) one that changeset graphs are a strictly more powerful representation than snapshot histories. This lesson has been thorougly absorbed and improved on in more recent VCS designs.
Brilliant and pioneering, but baroque to the point of unusability and superseded by later projects. Robert Collins wrote the epitaph on Arch when he abandoned Arch-2.0 development to start the baz project, and Tom Lord seemed to be recognising reality when he resigned the project leadership in 2005, leaving Arch without a maintainer. As the incomplete sample session shows, the implementation has since deteriorated to the point of unusability.
This analysis describes monotone version 0.35.
Monotone is decentralized, commit-before-merge, and has a changesets-based data model with container identity.
These features have become common in later VCSes influenced by monotone. Monotone has one property that remains unique, however: it is designed to make the trustworthiness of a repository (or any part of it) a provable derivation from the trust levels of the contributors' identities.
As with Arch, each revision in a repository is uniquely identified by a cryptographic hash of its contents. Every changeset in the repository includes a cryptographic hash derived from both the content of its child revision and the hash of its parent(s). Each changeset hash therefore incorporates information about all of the ancestral changesets in the repository clear back to the root node.
The changeset and revision hashes function as an integrity check on each other. Repository corruption (either unadvertent or as the result of an intrusion) will be detected and localized to an individual changeset any time the correctness of the hash chains us checked. Monotone does these checks as a matter of routine.
It is possible to add a “certifications” to a revision. This is a text annotation, signed with RSA public-key encryption by the author. The most common sort of certificate is a change comment; others might include (for example) and assertion that the asigner is the author of the changeset for this revision, or results from a test of the software, or notice that this revision is the root of a named branch.
Each certification therefore has a trust level derived from the trust level of the signer's public key. When monotone makes a decision about storing, transmitting, or extracting files, manifests, or revisions, the decision is often based on certs it has seen, and the trustworthiness you assign to those certs.
# Create a new monotone database # $mtn db init --db=$PWD/esr.mtn# Create a key pair for signing commits # $mtn genkey esr@thyrsus.commtn: generating key-pair 'esr@thyrsus.com' enter passphrase for key ID [esr@thyrsus.com]: confirm passphrase for key ID [esr@thyrsus.com]: mtn: storing key-pair 'esr@thyrsus.com' in /home/esr/.monotone/keys/ # Verify that the keypair exists # $mtn list keys[public keys] f6d40237ed2016d645d0f011d9148a0b30bbbe9c esr@thyrsus.com (*) (*) - only in /home/esr/.monotone/keys/ [private keys] 5f1f73264652892118d2b71aa7a958e3382dc5f9 esr@thyrsus.com # Set up a working directory for a new branch, com.thyrsus.example. # Branches need to be globally unique and are conventionally named # the same way Java packages are, using a reverse DNS name as a prefix. # $mtn --db=esr.mtn --branch=com.thyrsus.example setup example# Go to the working directory # $cd example# Create our standard example file # $echo "This is a one-liner file." >foo.txt# Add the file # $mtn add foo.txtmtn: adding foo.txt to workspace manifest # Look at the database status to verify it is there # $mtn statusCurrent branch: com.thyrsus.example Changes against parent added added foo.txt # Look at the creation action # $mtn diff# # old_revision [] # # add_dir "" # # add_file "foo.txt" # content [aa752ef3e3b0b33851e6774378272e579310a0ff] # ============================================================ --- foo.txt aa752ef3e3b0b33851e6774378272e579310a0ff +++ foo.txt aa752ef3e3b0b33851e6774378272e579310a0ff @@ -0,0 +1 @@ +This is a one-liner file. # Commit the add # $mtn commit --message="initial checkin of project"mtn: beginning commit on branch 'com.thyrsus.example' enter passphrase for key ID [esr@thyrsus.com]: mtn: committed revision e7f7849741ccbc7307026a9e8925b507ad2d7897 # List head revisions in the branch. There will be just one in this case # $mtn headsmtn: branch 'com.thyrsus.example' is currently merged: e7f7849741ccbc7307026a9e8925b507ad2d7897 esr@thyrsus.com 2008-01-09T16:36:11 # Modify the example file # $echo "Adding a second line" >>foo.txt# See that monotone knows it's been modified # $mtn statusCurrent branch: com.thyrsus.example Changes against parent e7f7849741ccbc7307026a9e8925b507ad2d7897 patched foo.txt # Commit the modification # $mtn commit --message="Second commit"mtn: beginning commit on branch 'com.thyrsus.example' mtn: committed revision c2bd55409ad2fd2defcbd67e958c8b1c6f64d091 # Display the revision log # $mtn logo ----------------------------------------------------------------- | Revision: c2bd55409ad2fd2defcbd67e958c8b1c6f64d091 | Ancestor: e7f7849741ccbc7307026a9e8925b507ad2d7897 | Author: esr@thyrsus.com | Date: 2008-01-09T16:37:41 | Branch: com.thyrsus.example | | Modified files: | foo.txt | | ChangeLog: | | Second commit o ----------------------------------------------------------------- Revision: e7f7849741ccbc7307026a9e8925b507ad2d7897 Ancestor: Author: esr@thyrsus.com Date: 2008-01-09T16:36:11 Branch: com.thyrsus.example Added files: foo.txt Added directories: ChangeLog: initial checkin of project
Commands in the summary have been left in the order and groupings in which they're listed by the output of mtn help
- asciik
Prints an ASCII representation of the repo graph.
- fdiff
Diff 2 files and output result.
- fload
Load file contents into db.
- fmerge
Merge 3 files and output result.
- get_roster
Dump the roster associated with the given REVID, or the workspace if no REVID is given
- identify
Calculate identity of PATH or stdin.
- rcs_import
Parse versions in RCS files.
- annotate
Print annotated copy of a file.
- cat
Write a file version from database to stdout.
- complete
Complete a partial id.
- diff
Show diffs between repo versions, or between repo and workspace.
- help
Display command help.
- list (ls)
Show database objects, or the current workspace manifest, or known, unknown, intentionally ignored, missing, or changed-state files. (11 subcommands)
- log
Print change history in reverse order.
- show_conflicts
Show what conflicts would need to be resolved to merge the given revisions.
- status
Show status of workspace.
- cert
Create a cert for a revision.
- dropkey
Drop a public and private key.
- genkey
Generate an RSA key-pair.
- passphrase
Change passphrase of a private RSA key.
- ssh_agent_add
Add your monotone key to ssh-agent.
- ssh_agent_export
Export your monotone key for use with ssh-agent.
- trusted
Test whether a hypothetical cert would be trusted by current settings.
- clone
Check out a revision from remote database into a directory.
- pull
Pull branches matching a specified pattern from a specified netsync server.
- push
Push branches matching a specified pattern from a specified netsync server.
- serve
Serve the database to connecting clients.
- sync
Synchronize branches matching a specified pattern with another server.
- privkey
Write private key packet to stdout.
- pubkey
Write public key packet to stdout.
- read
Read packets from files or stdin.
- approve
Approve of a particular revision.
- comment
Comment on a particular revision.
- disapprove
Disapprove of a particular revision.
- tag
Put a symbolic tag cert on a revision.
- testresult
Note the results of running a test on a revision.
- checkout (co)
Commit workspace to repository.
- explicit_merge
Merge two explicitly given revisions, placing result in given branch.
- heads
Show unmerged head revisions of a branch.
- import
Import the contents of the given directory tree into a given repository branch.
- merge
Merge unmerged heads of a branch.
- merge_into_dir
Merge one branch into a subdirectory in another branch.
- merge_into_workspace
Merge a revision into the current workspace's base revision.
- migrate_workspace
Migrate a workspace directory's metadata to the latest format.
- propagate
Merge from one branch to another asymmetrically.
- refresh_inodeprints
Refresh the inodeprint cache.
- setup
Setup a new workspace directory, default to current.
- add
Add files to workspace.
- attr
Set, get or drop file attributes. (3 subcommands)
- commit (ci)
Commit workspace to repository.
- drop (rm)
Drop files from workspace.
- mkdir
Make directories and add them to workspace.
- mv (rename)
Rename entries in the workspace.
- pivot_root
Pename the root directory.
- pluck
Apply changes made at arbitrary places in history to current workspace..
- revert
Revert file(s), dir(s) or entire workspace to repo versions.
- update
Modifies your workspace to be based on a different revision, preserving uncommitted changes as it does so.
The core idea of monotone's architecture is the commit-before-merge model of conflict resolution, and the associated scheme of a repository as a general DAG with lots of lightweight branches and casual merging. These represent a very significant advance on most previous VCSes.
Almost as important is the security, integrity, and trust model. While computationally expensive, it offers end-to-end guarantees not matched by any other VCS before or (as of early 2008) since.
In his Google Tech Talk on git, Linus Torvalds observed that he liked the design of monotone in 2005, but that its performance was “horribly bad” and he couldn't use it. Performance has since improved significantly, enough to be earn design wins from projects such as Pidgin and OpenEmbedded; Graydon Hoare plausibly asserts that, while it is still not suited for projects the size of the Linux kernel, monotone has become quite usable for repositories in the size range of 5K files, 10K commits, and a few dozen developers.
Monotone's author owns up, however, to the reality that monotone is unlikely to achieve the extreme speed of Mercurial or git. Some choices in the core algorithms and data representations trade away performance for integrity checking, and the cryptography techniques used throughout the design are compute-intensive.
The combination of a C++ core with the lua extension language is a competitive disadvantage against VCSes like Mercurial and bzr in which the core system and extensions are all one scripting language.
The monotone manual does a good job of explaining the system.
One critique can be found in Distributed version control systems. In general, reviews of Monotone have been very positive except on the performance issue.
The monotone security and trust model is strictly more powerful than has been implemented in more recent designs such as Mercurial, bzr, and git. There is a class of potential identity-spoofing attacks designed to inject bad code into a repository that these systems do not foreclose but which monotone (barring implementation bugs) would prevent.
The core design of monotone is extremely strong, but its author forthrightly admits it is not a production-quality tool and that the odds he will be able to bring it to production status in the future foreseeable in early 2008 are slim.
VCS users who like this design should choose one of the production-quality VCSes influenced by it, such as Mercurial or git. Other VCS designers should study monotone carefully. I believe there are still lessons here, especially in monotone's use of cryptography and certifications, that competing VCSes would do well to heed.
There's a folk saying that “It's not what you don't know that hurts you, it's what you think you know that ain't so.” In examining the pattern of development of VCSes, it seems to me that the this sub-field of computer science has been less hampered than most by difficulties in finding appropriate techniques, but more hampered than most by wrong assumptions that hung on far longer than they should have.
First wrong assumption: Conflict resolution by merging is intractably difficult, so we'll have to settle for locking. It took at least fifteen and arguably twenty years for VCS designers to get shut of that one. But it's historical now.
Second wrong assumption: Change history representation as a snapshot sequence is perfectly dual to the representation as change/add/delete/rename sequences.. This folk theorem is well expressed in the 2004 essay On Arch and Subversion. It is appealing, widely held, and dead wrong.
File renames break the apparent symmetry. The failure of snapshot-based models to correctly address this has caused endless design failures, subtle bugs, and user misery.
Practically speaking, failure to address this broken symmetry goes a long way towards explaining why CVS became such a disaster. But the damage didn't end there, which is why I'm courting controversy by pointing out that it underlies a debate about third-generation designs that is still live today. Should VCSes be purely content-addressable filesystems (the Mercurial and git approach) or should they have container identity (as in Arch, monotone, and bzr)?
That debate is not over, but at least VCS designers are grappling with it now.
I have a guess about the third wrong assumption. I think it goes something like this: The correct choice of abstractions, operations, and containers in a VCS is the one that makes the cleverest sorts of data-shuffling possible. I suspect that, as our algorithms get better, we're going to find that the best choices are not the most theoretically clever ones but rather the ones that are easiest for human beings to intuitively model..
This is why, even though I find constructions like today's elaborate merge theory fascinating to think about. I'm not sure it is actually going anywhere useful. Naive merge algorithms with poor behavior at edge cases may actually be preferable to more sophisticated ones that handle edge cases well but that humans have trouble anticipating effectively.
An even more interesting question is this: what are the fourth, and nth wrong assumptions — the ones we haven't noticed we're making yet?
David A. Wheeler's Comments on Open Source Software / Free Software (OSS/FS) Software Configuration Management (SCM) Systems was written in 2004 and is somewhat dated in spots, but includes descriptions of a number of VCSes I have not covered here. His analysis of Arch's strengths and weaknesses is particularly good.
Rick Moen compares a very long list of VCSes, many of them obscure obscure and proprietary.
Graydon Hoare, author of monotone, was very illuminating about the history and fundamental concepts of third-generation VCSes.
Karl Fogel, one of the founders of the Subversion project, read a draft carefully and corrected several points of history and technicalia.
Ted T'so contributed important historical information.
A. A Chat with Graydon Hoare
This is a lightly edited log of an IRC conversation that took
place on 12/12/2007 between 00:39 and 03:30 UTC on the monotone channel. The main
participants were Eric S. Raymond <esr@thyrsus.com>),
Graydon Hoare <graydon@pobox.com>, and Daniel Carosone
<dan@geek.com.au>, using the handle
“uep”. “ronny” is Ronny Pfannschmidt. Hoare
is the principal author of the monotone VCS and Carosone one opf his
senior collaborators.
Joins and leaves have been removed. Typos, capitalization and punctuation have been fixed. URLS have been added. Pronouns have often been replaced by their referents. One date I misremembered has been corrected. Some irrelevant chatter has been excised and some remarks reordered to join conversational spans that were separated by accidents of IRC timing. Editorial content insertions are marked [like this].
<esr> I'm writing a comparative review of 3G VCSes and have some questions about monotone. Is the author here?
<graydon> Yeah.
<graydon> I'm curious if you're the esr who is somewhat more well known by those initials.
<esr> Yes, that would be me.
<graydon> Ok. what's up?
<esr> I'm writing this comparison because I'm facing the question of what 3G system to move to. But I like thinking about VCSes, so I decided to do a really thorough analysis rather than the bare minimum necessary for the decision. And then publish it. Seems to me something like this is needed.
<graydon> Sure. I'll give you biased answers to everything but that's to be expected :)
<esr> Actually one of the reasons I've been looking for you is a blog comment you wrote that I was very impressed by. [Far from being biased,] you seem to have an attitude about VCS-related issues that I consider judicious and wise.
<esr> I want to grill you about monotone, but I'd also like you to be one of the reviewers on my draft.
<graydon> We've had several people write up comparisons in the past, but more can't possibly hurt!
<graydon> I imagine you would want to compare at minimum monotone, darcs, mercurial, git and bzr, but possibly also arch and some others... there's a long-ish list of other people playing in this space linked to on the monotone webpage.
<esr> You nailed the list.
<esr> I'm going to mention BitKeeper for historical reasons, and I have a bit on the history of Arch and a dissection of CVS. But you've named the ones I intend to analyze in detail.
<graydon> Sure. It's a field that goes way back, you can find interesting material written all the way back to the dawn of computing :)
<esr> Have you written anything like a white paper describing Monotone's objectives, philosophy, and implementation?
<graydon> Not really. I wrote the manual.
<graydon> There were a bunch of objectives, only some of which have been fully met (yet).
<graydon> Some have been quite exceeded though. I didn't expect, for example, the chained cryptographic DAG formalism to pop up. That turned out to be hugely powerful.
<graydon> Nor did I expect or intend for the work on the mark-merge algorithm.
<esr> Yes, [the chained cryptographic DAG is] a very appealing and natural way to check data integrity.
<graydon> It's not just integrity, that's sort of an after-effect.
<esr> What was the primary intention?
<graydon> The main point is that it's a safe append-only distributed data structure with no central coordination, no synchronization, no locks or clocks.
<graydon> You define a merge operator for joins in the DAG and you get free, scalable, safe parallelism.
<graydon> You don't need a naming system or a messaging system or anything. you can just flood updates around, because the node names are assigned uniquely by the accumulation of history and the merge operator.
<esr> Yeah. I see a lot of convergence with Matt Mackall's work on Mercurial in your data-structure design. I think you were there first, though. Do you think you influenced him?
<graydon> Careful when you say "you". I didn't invent this DAG structure. Jerome Fisher sent the idea to me in private email, so IMO he invented it. Though when we tried to establish whose idea it was, the Codeville guys said they independently invented it too. It's a *great* structure.
<graydon> In fact, it's not present in the first two years of monotone development, and there's lots of old crusty code that makes that evident. The structure got redesigned several times during development.
<graydon> Anyways, yes, I think Mercurial and git both lifted this idea verbatim from us. I'm happy it spread. It's a great idea.
<graydon> I don't think they make any sort of secret of that fact. There's a lot of concurrent "discovery" of the same points over and over.
<esr> I'm not a bit surprised. I invented some of the fundamental ideas in 3G VCS myself, back around 1995, but I was busy and never followed up. Didn't publish, either, drat it :-)
<graydon> *shrug* Publishing an idea is one thing, publishing a tool is another. it takes a lot of work, and even then, some kernel hacker is likely to come along and beat you at your own game :)
<esr> I have noticed that all the 3G systems look *remarkably* similar. And remarkably simple.
<graydon> Well, there is a lot of cross-pollination
<graydon> The earliest version of monotone looked a lot like darcs, actually, but I couldn't figure how to synthesize commutators in all cases so I gave up and switched to a graph model. General graphs, initially, because I didn't see how to construct the DAGs.
<graydon> We study one another's work!
<esr> darcs predated monotone?
<graydon> Um, I think they got released around the same time.
<graydon> Actually I think I might have published first since I remember seeing the darcs page and thinking "damn, if only he'd done that a year ago I wouldn't have bothered with all this!"
<graydon> But then, that might have been just before I published. I showed monotone to some friends first to get their reactions. most hated it :)
<graydon> Anyways it was a tiny program then. it's grown quite a bit, and as I say, been rewritten several times
<graydon> Or, mostly. some bits are in their initial state.
<graydon> Tom Lord definitely published Arch before me, but not before I had started. By the time he published I was far enough into monotone that I didn't feel like jumping ship. I also didn't like the Arch implementation.
<graydon> I'm not really concerned with the publication order though. all the 1st drafts of these tools were pretty junky.
<graydon> And it was obvious to a lot of people what had to be written, I think. BitKeeper set an obvious target to beat.
<esr> Yes, it did.
<esr> And a lot of these ideas were in the air before BitKeeper. (Heck, even *I* influenced BitKeeper's design a bit [and I'm not really a player in this area].)
<graydon> Yeah. it's an obvious direction to take things. the trick is in getting all the math right :)
<esr> I don't think much of darcs as a practical system -- they've got a *serious* conflict bug that you probably know about -- but the theoretical stuff on patch algebra bears watching.
<graydon> Math, protocols, formats... it's all very fiddly and unsatisfying details after a while!
<graydon> PRCS looked promising for a while too!
<graydon> I know a good number of people who still love darcs, so I wouldn't give up hope. It's lightweight and easy.
<esr> Saving your presence, my preliminary evaluation is that Matt Mackall has come closest to getting the balance right. I could have my mind changed about that though, and you might be the person to do it.
<graydon> *shrug* I am not likely to talk you out of that position.
<graydon> I work at Mozilla and had the unenviable task recently of talking them all into using Mercurial instead of monotone
<esr> Oh? Why?
<graydon> Because it suits the needs of our project better, at this point.
<graydon> Mercurial scales better, it has a bunch of UI features that users enjoy that monotone strictly lacks, it pushes over HTTP to plain hosts better ... you know, same reasons everyone gives :)
<graydon> If I were paid to work full time fixing up monotone I might be able to bring it back up to competitive position on these points, but only so close, and I'm *not* paid to do that.
<graydon> I work on languages and JITs and garbage collectors and whatnot :)
<esr> So, um, what does monotone still offer? Serious question; this is exactly the kind of comparison I want to do.
<graydon> A few things:
<graydon> The [file tree] merge algorithm is stronger, as is its management of the directory structure.
<uep> For me, the integrity (including signatures) capabilities are a big winner
<graydon> monotone actually has a concept of an inode, essentially, and the merge algorithm has ways it provably wins where the competition's loses. so I prefer merging under it.
<uep> The others, even with the chained hashing data structure similarities you already discussed, make this a secondary point.
<graydon> The signatures are important for some people too. we sign every revision, and we keep this stuff as an audit trail in every database.
<uep> For example, they conflate the trust model of "passing information around" with the trust model of "trusting this information for the purpose at hand".
<uep> A huge amount of power comes from keeping them clearly distinct.
<graydon> Mercurial and git essentially lose the audit trail on every transmission event. when I pull from server X, the fact that I trusted the contents of server X at that moment is lost. When someone subsequently pulls from me, they have no idea I got it from server X.
<esr> Ahhhhhhh. Interesting point!
<uep> (And some of the UI and process confusion also comes from not assuming a particular way of doing things as a result, alas.)
<graydon> That's sort of dangerous. Potentially -- I'd argue "likely" -- someday there will be a serious transitive trust attack on one of these systems. you only have to fool one person near the edge into believing that you're Alan Cox.
<esr> Very telling.
<graydon> Now, they can patch over this by using signed tags.
<graydon> If they tag and sign every rev, they get what we do.
<graydon> But they seldom sign anything except releases.
<graydon> Our whole naming system is based on certificate-issuing.
<graydon> So, slightly different there.
<uep> So, I can relay a revision from author-a to user-b, without trusting that content myself, and user-b can still see and make their own decisions on how to use that content
<graydon> I'm hesitant to make a big deal of it though, because you never really want to fight on security features. it's entirely possible that you can subvert monotone with some arithmetic error in our crypto system or an unhandled race condition or some trivial concern...
<esr> Wise of you.
<graydon> Yeah. monotone's design is based on complete ignorance of the communication path. It was intended to flood through netnews initially.
<uep> I can use (trust) that revision in one workspace that accepts experimental changes (eg, because I want to review them!) but not in another workspace that should only take revisions with additional blessing.
<uep> I wrote some of the bits of the manual that graydon didn't, and several bits of the wiki that people seem to find inspiring.
<uep> e.g., the page on "DaggyFixes" which people keep telling me is the bit that suddenly makes them See The Light.
<graydon> (Yeah, when I say "I wrote such-and-such", I really only mean initial versions; I haven't written more than 50% of what ships in monotone anymore. There's gobs of new stuff by others. Probably even less than that.)
<uep> (daggy fixes is not specific to monotone, but it's a good development practice that monotone happens to support especially well.)
<uep> esr: The transport-independent trust model also offers another big bonus, as well as the issues around transitive trust attacks.
<esr> graydon: From what you're telling me, I suspect that monotone's role in the future will be mainly as a good influence on other systems.
<uep> You can append and publish additional certs on exiting revisions at any time. This is ideal for "blessing" revisions for additional purposes, post commit, e.g. by autobuild/testsuite tools, or by additioanl code-review authors.
<uep> This removes a strong disincentive to commit that exists in other systems (where things don't get committed until they have been reviewed, meaning you can't use the tool to facilitate the review)
<uep> esr: As for being a good influence on others -- we hope it will be much more than that, but we hope to be that too, certainly.
<graydon> The speed issue is ... delicate.
<graydon> Again, we have a design difference that sort of goes deep
<graydon> We keep the network form, disk form, and memory forms separate
<graydon> And when we transform between them, we analyze, verify, reconstruct caches on the fly, etc.
<graydon> Our competitors largely work through byte-copies of pack files, revlogs, etc.
<uep> Not all of the speed issue stems directly from that, but certainly some do.
<graydon> It's hard to compete with sendfile().
<uep> esr: Quite a bit of this philosphy is in the manual and wiki (though, as with all documentation, it could always be better).
<graydon> No, sqlite is also a bottleneck in a way, though mostly just the completely random page access order you get when working with btrees keyed by cryptographic hashes :)
<graydon> That'd be true of any "simple" backend though :)
<ronny> Also hg/git are quite easy to extend with new commands/plugins.
<graydon> Yeah, they benefit from not being written in my paranoid dialect of C++. or C++ in general.
<graydon> Benefit ... evolve faster anyways.
<ronny> monotone is rather monolithic about that.
<graydon> Lots of churn :)
<ronny> Being hard to extend sucks - can't get me the features I want in any reasonable time
<graydon> Linus has recently decided to make a habit of describing monotone's dialect of C++ as over-abstract and OO, which suggests he simply hasn't read it. It's quite low level. it just does a lot of work to log what's happening and avoid memory errors :)
<esr> graydon: Pointer? [A bystander pointed me to http://lwn.net/Articles/249460/] a few seconds later.]
<graydon> esr: Oh, I do not want to get into that ... just to point out that people generally feel our code is hard to approach.
<graydon> Unless they have a very specific dialect of C++ that they like.
<ronny> I think being easy to extend [a VCS or use it] as a library is a very big benefit.
<graydon> ronny: It's not without costs, and they were costs I did not want to bear.
<esr> Well, I'm afraid I'm a C++-hater myself. I like the fact that a lot of the new VCSes are written in Python.
<graydon> monotone's *implementation* is perhaps best understood as "what would cause me the least grief picking through crash dumps".
<graydon> So script code that does a lot of work, or library interfaces, or raw pointer twiddling ... I wanted to avoid all this stuff.
<graydon> I've preferred to add hooks and automate commands as needed, rather than assume that the whole tool needs to be in a script language.
<graydon> This is a conservative stance based on the belief that fewer such needs exist than people imagine, and the need for them is outweighed by the need for predictable and stable parts.
<graydon> I apologize for this stance if conservatism makes you angry, but on the other hand, I think it unrealistic at this point to make a fuss over it. monotone is not suddenly going to rewrite itself in a scripting language.
<graydon> I don't understand why people must get so full of anger at languages they dislike using.
<graydon> I have a whole spectrum of languages I'm not terribly fond of, but I can see what the designers and users were thinking, I can respect them at least...
<graydon> I'm not even terribly fond of C++, but so what? life's too short to be this full of anger over such matters.
<esr> graydon: OK, myself I think the rapid-prototyping advantages of Python more than outweigh the potential stability problems.
<esr> Stability you can get by being disciplined, but you can't get rapid-prototyping flexibility out of C++.
<esr> I'm a senior dev on a big C++ project right now [Battle For Wesnoth]. Love the project; hate the language.
<graydon> Depends on the sub-dialect. I dislike memory errors so I'm pretty diligent about not using raw pointers.
<graydon> That removes most of the pain.
<graydon> Anyways, I don't wish to argue language, as I said. I can talk about programming languages until I am literally the last one standing. Let's not do it!
<uep> Yeah. I'm well far from a C++ fan by any description, I'm mostly unfamiliar with it in practical usage.
<graydon> C++ is not my favourite, but it was OK on the design space at the time. maybe it was a bad idea. can't go back.
<uep> But monotone's C++ is not normal C++.
<graydon> I actually wrote it in OCAML at first if that makes you feel better :)
<esr> Weirdly enough, it does. I'm an old LISP-head, if that helps you understand.
<uep> We still have OCAML in some of the supplementary tools, like the GTK graph visualiser.
<graydon> My first two jobs were professional scheme programming, but my heart mostly belongs to the MLs...
<graydon> Well, not really.
<graydon> They're just the closest to what I like. I really want languages to do much more static reasoning than that. but I have to write my own languages to get much better.
<graydon> esr: Some other cross-pollinations you might be interested to note...
<graydon> We also have a cute stateless and symmetric flooding network protocol.
<graydon> You can just say "sync" against N different hosts, and everyone winds up with the same stuff, which is nice and mindless, relative to the competition.
<graydon> But I'm not sure it matters so much.
<esr> In today's world of near-zero-cost point-to-point between any two IP addresses, probably not so much.
<graydon> Our merge algorithm was jointly developed with the Codeville guys (Cohen brothers [Bram and Ross]) after a lot of chatter about whether or not the Bitkeeper weave mechanism made for a better merge system.
<graydon> There's a website, revctrl.org, that chronicles all the things they worked out. njs [Nathaniel J. Smith] and tbrownaw [Timothy Brownawell] did a lot of the work on it, IIRC.
<graydon> Also, hmm... our storage system uses a version of xdelta I wrote, but xdelta itself is Josh MacDonald's work, which was originally for PRCS / PRCS2. (He's still churning out xdelta releases, it seems, on xdelta.org.)
<graydon> And strangely, it seems that Daniel Berlin hand-translated my xdelta implementation back to C and fed it back up into Subversion, which now uses it :)
<graydon> I'm not sure if there's a lot else interesting. the LCS algorithm we use is only implemented in one other place (Aubrey Jaffer's SCM library) but it's not clear to me that it matters. we only use it when line-merging, quite late in the game...
<graydon> Our sync algorithm really does have one very clever part that gets you reconciliation of 2 arbitrary sets with no historical relationship in in log(D) communication, where D is the size of the difference between their respective collections.
<graydon> Alas, since we moved to using DAGs this is sort of a triviality. it mattered more for general graphs.
<graydon> As far as I know this sync algorithm is going to be lost in the mist when we rip it out, which is a shame. it'd make a nice replacement for any set-based flooding system.
<graydon> I almost thought to remove it and write an rsync-like tool that just did that task alone, over a filesystem, to preserve the functionality.
<graydon> It's handy for unioning maildirs and whatnot :-)
<graydon> But yeah, if communication is free now, maybe reading the remote side completely is just as cheap.
<graydon> Um, oh, it might be worth studying the merge algorithms. People don't talk about them a lot but there's a lot of curious subtlety in there.
<graydon> You'll notice if you look that monotone now has an explicit lifecycle model for every inode.
<esr> I want to get a better understanding of what you mean by inodes and "explicit lifecycle model".
<graydon> Um, well, what happens when I copy a file? or move a file? or add one, then delete it, then add another with the same name?
<graydon> These events all mean things to users, or so users say.
<graydon> But if you look at snapshots before and after the events, you don't always see them.
<esr> Ahhh, I see. Your inode is a file ID that doesn't change even if the file name does.
<graydon> Yeah, in that sense. also you can't turn a file into a directory or vice-versa, and various other sanity conditions.
<graydon> A full inode model is expensive to maintain but users often prefer it.
<graydon> Initially we didn't. We modeled snapshots of trees. Just files actually: directories were implicit. This is exactly what git and Mercurial currently do.
<graydon> Then I gave up since I was synthesizing an inode model on the fly using heuristics anyways, and just explicitly encoded it into the model we write to disk and transfer over the wire.
<graydon> Tom Lord told us early on that the number of merge heuristics we'd have to kludge in if we didn't model node lifecycle explicitly would be unbearable. I said I'd wait and see. after about two years of adding heuristics I came to the conclusion he was right, and gave up.
<graydon> Strangely, I am not certain that "arch 2.0 / revc" continued that line of reasoning; I think Tom was going to adopt the git model again.
<graydon> So, design ideas slish and slosh back and forth, but all these systems essentially have two levels of merge operation: reconciling trees, then within those trees, reconciling any files that conflict.
<graydon> So, you wind up using two different, possibly *very* different, merge algorithms for node reconciliation in trees and line reconciliation in files.
<graydon> I think monotone's node reconciliation algorithm is the most predictable and least failure-prone out of the bunch. That's the multi-mark-merge thing on revctrl.org.
<esr> OK, I'm walking away more impressed than when I came in. You have some excellent core ideas and you're both lucid and balanced about expressing them.
<esr> I think a lightly edited version of this log might have to be an appendix of my paper. It's been that helpful.
In subsequent email, on 26 December 2007, Hoare noted: “ Linus caught us at a particularly bad time: he ditched BitKeeper just after Nathaniel J. Smith and I had finished landing some very performance-negative code (the first, very rough form of the cryptographic DAG code) and I had gone on vacation for 3 months in Germany. No way to really talk through the problems. By the time we had settled on what he would consider acceptable performance improvements, he had a prototype of git knocked out. By the time I had my boxes unpacked in my new home and was getting serious about profiling and tuning, Mercurial had leapt into existence too.”